

1.软连接和硬链接的区别
1、本质不同
硬链接:同一个文件,多个名称。
软链接:不同的文件。
2、跨分区
硬链接:不支持跨分区。
软链接:支持跨分区。
3、目录
硬链接:不支持对目录创建。
软链接:支持对目录创建。
4、相互关系
硬链接:删除某一个硬链接,另一个硬链接不影响使用。
软链接:原始文件和软链接有依赖关系,原始文件删了,软链接就失效了。
5、inode编号
硬链接:inode编号是相同的。
软链接:inode编号不同。
6、链接数
硬链接:删除一个硬链接,硬链接的链接数会有变化。
软链接:删除一个软链接,链接数不会有变化,删除的相当于是一个文件(或快捷方式)。
7、相对路径:原始文件路径
硬链接:硬链接的相对路径,是相对的当前工作目录的相对路径。
软链接:软链接的原始文件路径是,相对的软链接的相对路径,而不是相对当前工作目录。
8、文件类型
硬链接:硬链接的文件类型是,原来是什么就是什么,例如:原来是普通文件,还是普通文件。
软链接:软链接的文件类型是L
9、命令的实现不一样
硬链接:ln
软链接:ln -s
2.Linux的目录结构
1. 根目录(/)
根目录是整个文件系统的顶级目录,所有其他目录和文件都是从根目录开始的。在Linux中,根目录用斜杠(/)表示。
2. /bin
/bin目录包含一些基本的可执行文件,这些文件是系统启动和运行所必需的。例如,/bin目录包含常用的命令如ls、cp、rm等。
3. /boot
/boot目录包含启动加载程序(bootloader)的相关文件,包括内核映像文件和引导配置文件。在启动过程中,系统会使用/boot目录下的文件来引导操作系统。
4. /dev
/dev目录包含设备文件,这些文件用于与系统中的设备进行交互。在Linux中,一切都被视为文件,设备文件用于访问硬件设备,如磁盘、键盘、鼠标等。
5. /etc
/etc目录包含系统的配置文件。这些配置文件用于设置系统的各种参数和选项,例如网络配置、用户账户配置、服务配置等。/etc目录中的文件对系统的正常运行至关重要。
6. /home
/home目录是用户的主目录,每个用户都有一个与其用户名相对应的子目录。用户可以在自己的主目录中存储个人文件和配置。
7. /lib和/lib64
/lib目录和/lib64目录包含共享库文件,这些库文件是应用程序和系统工具所需的共享组件。/lib目录用于32位系统,而/lib64目录用于64位系统。
8. /media
/media目录用于挂载可移动设备,如光盘、USB驱动器等。当插入可移动设备时,系统会自动将其挂载到/media目录下的子目录中。
9. /mnt
/mnt目录用于临时挂载其他文件系统或网络共享。管理员可以将其他设备或远程共享挂载到/mnt目录中,以便访问其内容。
10. /opt
/opt目录用于安装第三方软件包。一些应用程序将其安装在/opt目录下,以便与系统的其他部分分离。
11. /proc
/proc目录是一个虚拟文件系统,提供有关系统和进程的信息。系统管理员和开发人员可以通过读取/proc目录下的文件来获取关于系统状态、进程信息、硬件配置等的实时数据。
12. /root
/root目录是超级用户(root用户)的主目录。与普通用户的主目录(/home)不同,超级用户的主目录位于/root。只有root用户可以访问和操作/root目录。
13. /sbin
/sbin目录包含系统管理员使用的一些系统命令和工具。这些命令和工具通常用于系统管理和维护任务,例如启动和停止服务、网络配置等。
14. /srv
/srv目录用于存储系统服务提供的数据。例如,Web服务器可以将网站数据存储在/srv目录下。
15. /tmp
/tmp目录用于存储临时文件。该目录中的文件通常在系统重新启动后被删除。应注意定期清理/tmp目录,以确保不会占用过多的磁盘空间。
16. /usr
/usr目录包含用户的应用程序和文件。这是Linux系统中最大的目录之一,它通常包含共享的可执行文件、库文件、文档、图标等。
17. /var
/var目录用于存储可变数据,例如日志文件、缓存文件和临时文件。/var目录中的数据通常在系统运行时会频繁变化。
18. /run
/run目录是一个临时文件系统,用于存储在系统引导过程中需要保存的运行时数据。例如,PID文件、锁文件等。
19. /run/user
/run/user目录包含与用户相关的运行时数据。每个用户都有一个与其用户ID相对应的子目录,用于存储用户特定的运行时数据。
20. /sys
/sys目录是一个虚拟文件系统,用于提供关于系统硬件和设备的信息。它是与/sys目录下的文件进行交互的一种方法。
21. /srv
/srv目录用于存储系统服务提供的数据。例如,Web服务器可以将网站数据存储在/srv目录下。
3.Linux系统的启动流程
其过程可以分为5个阶段:
- 内核的引导。
- 运行 init。
- 系统初始化。
- 建立终端 。
- 用户登录系统。
具体可参考菜鸟:https://www.runoob.com/linux/linux-system-boot.html
4. 删除修改时间超过60分钟的.log格式的文件
find /var/log/nginx/ -mmin +60 -name "*.log" -exec rm {} \;5.查看操作系统版本,内核版本等
uname
-a 或--all 显示全部的信息,包括内核名称、主机名、操作系统版本、处理器类型和硬件架构等。。
-m 或--machine 显示处理器类型。
-n 或--nodename 显示主机名。
-r 或--release 显示内核版本号。
-s 或--sysname 显示操作系统名称。
-v 显示操作系统的版本。
--help 显示帮助。
--version 显示版本信息。
-p 显示处理器类型(与 -m 选项相同)。
uname -v -r6.Buffer 与 Cache
Cache
缓存区,是高速缓存,是位于CPU和主内存之间的容量较小但速度很快的存储器,因为CPU的速度远远高于主内存的速度,CPU从内存中读取数据需等待很长的时间,而 Cache保存着CPU刚用过的数据或循环使用的部分数据,这时从Cache中读取数据会更快,减少了CPU等待的时间,提高了系统的性能。
Cache并不是缓存文件的,而是缓存块的(块是I/O读写最小的单元);Cache一般会用在I/O请求上,如果多个进程要访问某个文件,可以把此文件读入Cache中,这样下一个进程获取CPU控制权并访问此文件直接从Cache读取,提高系统性能。
Buffer
缓冲区,用于存储速度不同步的设备或优先级不同的设备之间传输数据;通过buffer可以减少进程间通信需要等待的时间,当存储速度快的设备与存储速度慢的设备进行通信时,存储慢的数据先把数据存放到buffer,达到一定程度存储快的设备再读取buffer的数据,在此期间存储快的设备CPU可以干其他的事情。Buffer一般是用在写入磁盘的,例如:某个进程要求多个字段被读入,当所有要求的字段被读入之前已经读入的字段会先放到buffer中。
7. 设置用户下次登录必须修改密码
passwd -e 用户名8.sudo和su的区别
su
su命令是Linux系统中用于切换到其他用户身份的命令。通常,它需要超级用户(root)的密码才能切换到其他用户。使用su命令时,用户可以切换到其他用户的账户,并获得该账户的权限,如同该账户本身的操作一样。
su 用户名 ,与su -用户名 的不同之处如下:
- su -用户名 切换用户后,同时切换到新用户的工作环境中。
- su 用户名 切换用户后,不改变原用户的工作目录,及其他环境变量目录。
sudo
sudo命令是Linux系统中的一个命令,用于以超级用户(root)的权限执行特定命令。与su命令不同,sudo命令允许普通用户以自己的密码执行特权操作,而无需知道超级用户的密码。使用sudo命令时,用户需要在命令前加上sudo关键字,并输入自己的密码来确认身份。
如何添加用户,使其拥有 sudo 权限?
vim /etc/sudoers 9. 配置dir目录下新建文件自动赋予user1用户的可读可写权限
setfacl -m u:user1:rx /dir
#不会继承父级目录的权限
setfacl -m d:u:user1:rx /dir
# 在前面加上一个d,就可以设置默认facl权限10. 文件的特殊权限
suid
suid 属性只能运用在可执行文件上,含义是开放文件所有者的权限给其他用户,即当用户执行该执行
文件时,会拥有该执行文件所有者的权限。如果给一个非二进制文件文件附加 suid 权限,则会显示大
写S,属于无效。
chmod u+s 文件名sgid
sgid 属性可运用于文件或者目录,运用在文件的含义是开放文件所属组的权限给其他用户,即当用户
执行该执行文件时,会拥有该执行文件所属组用户的权限。如果给一个非二进制文件文件附加 sgid 权
限,则会显示大写S,属于无效。
chmod g+s 目录名/文件名sticky
sticky 权限只能运用于目录上,含义是该目录下所有的文件和子目录只能由所属者删除,即使其的权限
是777或者其他。一个公共目录,每个人都可以创建文件,删除自己的文件,但不能删除别人的文件(仅
对目录有效)。
chmod o+t 目录名11. 僵尸进程和孤儿进程如何产生如何处理
子进程和fork( )系统调用
要想了解孤儿进程和僵尸进程,我们首先需要了解子进程这个概念。
- 进程在执行期间,可以通过fork( )系统调用来创建一个属于自己的子进程。这时,称调用fork的进程为父进程,由fork创建的进程为该父进程的子进程。一般而言,父子进程共享代码段,但对于数据段、栈段等其他资源,父进程在调用fork函数时会将该部分资源完全复制到子进程中去,父子进程对该部分的资源并不共享。
- 创建完子进程后,父进程从fork( )的返回点继续执行,而子进程也是从fork( )的返回点开始执行。一般而言,要么先执行子进程,要么父子进程并行执行(这取决于操作系统设计者的设计)。
- 父进程通过调用wait( )系统调用来将其子进程回收释放。
僵尸进程
进程已经终止,但其父进程仍未调用wait( )将其回收,则该进程为僵尸进程(此时父进程并没有终止)。一般而言,僵尸进程只是短暂存在,当其被父进程回收释放时,那么该进程便不再存在。
- 孤儿进程与僵尸进程的共同点是进程都是子进程,且都已执行完成,但仍未释放资源;区别在于其父进程是否已经终止。
- 僵尸进程有可能会变为孤儿进程。
孤儿进程
其父进程已经终止,但父进程没有调用wait( )将其回收,那么该进程为孤儿进程。
如何处理僵尸进程
处理僵尸进程,实际上就是父进程调用wait( )系统调用回收执行完的子进程的过程。
父进程在执行完成后都会通过调用exit( )系统调用来对自己进行释放回收。
在每一个进程的PCB中都存储了进程对应的状态,当进程执行完毕时,我们会将其状态设置为DEAD状态。
因此,僵尸进程可以通过下方方法进行处理:
- 当父进程执行完成后,调用exit( )前,首先调用wait( )来回收已执行完成的子进程。
- wait( )的实现规则为:
- (1)在wait函数中,它会一直循环查找调用wait系统调用的这一进程的子进程(每一个父进程都会有一个子进程队列,查找时顺序查找该队列)。如果所有进程都查找了一遍都没有当前进程的子进程,说明该进程已经不存在子进程,那么我们直接返回,结束函数;
- (2)如果查找了一遍发现存在子进程,但子进程的状态都不为DEAD,那么我们调用schedule( )函数去执行其他进程或线程,该进程等待下一次分配cpu时间再从头寻找子进程;(schedule函数是进程调度函数)
- (3)如果在查找的过程中发现了一个状态为DEAD的子进程,那么这就是我们要释放的子进程,我们将其释放;
如何处理孤儿进程
在这里我们需要知道,父进程是如何通过调用exit( )来回收自身的。
实际上,当父进程执行结束后(亦或者是时间片用完),会立即调用schedule函数来将就绪队列中的下一个进程换上cpu。而在schedule函数中,首先判断当前进程是否已执行完毕,即检查状态是否为DEAD,如果为DEAD则会调用exit( )将其回收释放,然后再换上就绪队列中的下一个进程。
据此,我们可以设置一个专门存放状态为DEAD的进程的队列,通过在schedule函数中回收该队列的进程来实现对孤儿进程的回收。
12. Linux中,ctrl+c的原理
在Linux终端上敲“Ctrl+c”,就产生一个“中断”,会产生SIGINT信号,终端将其发送到该终端的前台进程组中的每一个进程,接着就会处理这个“中断任务”(默认的处理方式为结束掉当前进程)。
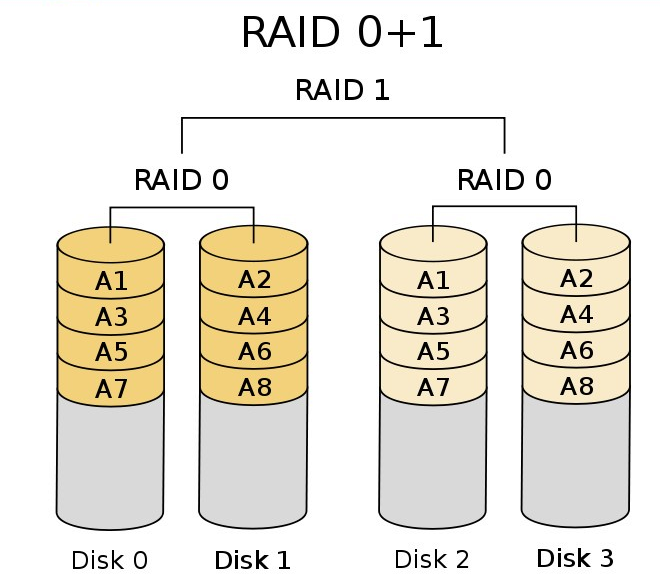
13.RAID0,1,5,01,10的区别和各自的优缺点
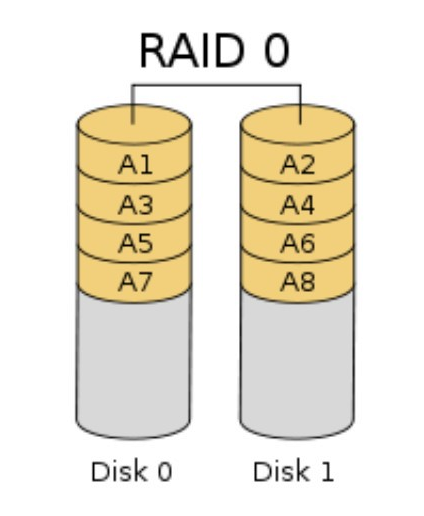
RAID0
数据存在多块硬盘,可以同时读多块硬盘,加快读的速度,但是缺点也明显,故障率也会提高
RAID1
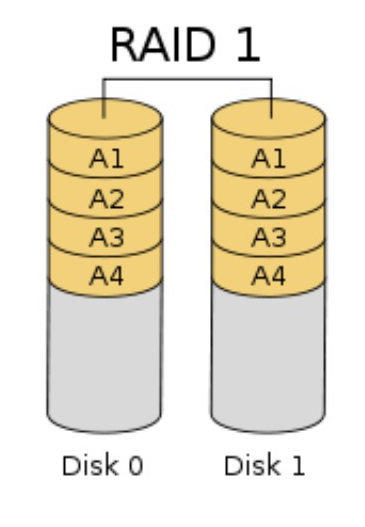
数据多块磁盘放相同的数据,可以用来进行备份冗余,保障数据的安全,但是不会对读的速度有帮助
RAID5
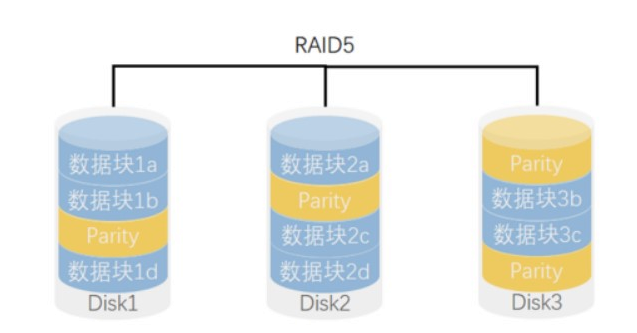
当RAID5的一个磁盘数据损坏后,利用剩下的数据和相应的奇偶校验信息去恢复被损坏的数据。
写性能较差,每次在写的时候要先读其他盘,来确定奇偶校验位,读性能较好,可以多块盘一起读。
RAID10
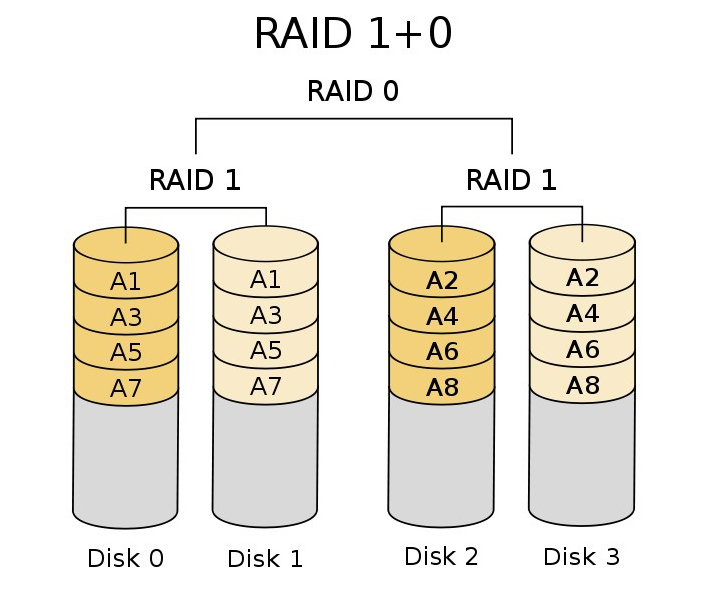
先做RAID1再做RAID0
这种架构的优势在于既兼顾了系统冗余有拥有读取分块加速能力,故障率较低,缺点是由于该架构较为复杂,一份数据需要至少四块硬盘才能够架构,比较费盘。
RAID01
先做RAID0再做RAID1
这种架构的安全性低于raid10,而两者由于IO数量一致。读写速度相同,使用的硬盘数量也一致。
所以raid10比raid01是一种更为先进的架构。
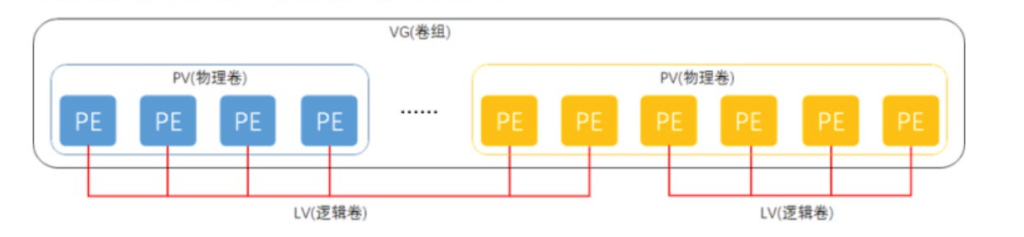
14.LVM中几个组件的关系(LV,PV,PE,VG)
先创建PE,然后把PE整合为VG,之后再把VG变为LV,LV就可以被拿去挂载使用了
15.selinux,iptables,firewalld的关系和区别
16.iptables中的五链四表
五链
iptables命令中设置数据过滤或处理数据包的策略叫做规则,将多个规则合成一个链,叫规则链。
PREROUTING
- 在进行路由判断之前所要进行的规则(DNAT/REDIRECT)
INPUT
- 处理入站的数据包
OUTPUT
- 处理出站的数据包
FORWARD
- 处理转发的数据包
POSTROUTING
- 在进行路由判断之后所要进行的规则(SNAT/MASQUERADE)
四表
iptables中的规则表是用于容纳规则链,规则表默认是允许状态的,那么规则链就是设置被禁止的规则,而反之如果规则表是禁止状态的,那么规则链就是设置被允许的规则。
raw表
- 确定是否对该数据包进行状态跟踪
mangle表
- 为数据包设置标记(较少使用)
nat表
- 修改数据包中的源、目标IP地址或端口
filter表
- 确定是否放行该数据包(过滤)
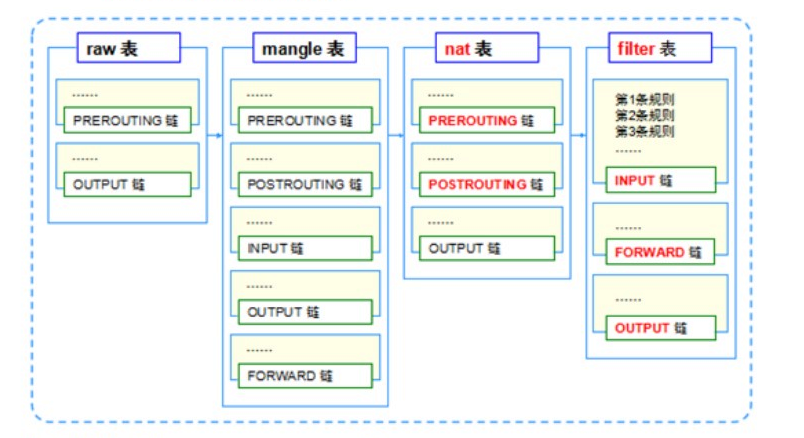
规则表的先后顺序:raw→mangle→nat→filter
规则链的先后顺序:
入站顺序
- PREROUTING→INPUT
出站顺序
- OUTPUT→POSTROUTING
转发顺序
- PREROUTING→FORWARD→POSTROUTING
17.firewalld如何放行端口
firewall-cmd --permanent --zone=public --add-port=8080 18.cron计划任务的表达式(分时日月星期)
分 时 日 月 星期 命令
* 表示任何数字都符合
0 2 * * * /run.sh # 每天的2点
0 2 14 * * /run.sh # 每月14号2点
0 2 14 2 * /run.sh # 每年2月14号2点
0 2 * * 5 /run.sh # 每个星期5的2点
0 2 * 6 5 /run.sh # 每年6月份的星期5的2点
0 2 2 * 5 /run.sh # 每月2号或者星期5的2点 星期和日同时存在,那么就是或的关系
0 2 2 6 5 /run.sh # 每年6月2号或者星期5的2点
* /5 * * * * /run.sh # 每隔5分钟执行一次
0 2 1,4,6 * * /run.sh # 每月1号,4号,6号的2点
0 2 5-9 * * /run.sh # 每月5-9号的2点
* * * * * /run.sh # 每分钟
0 * * * * /run.sh # 每整点
* * 2 * * /run.sh # 每月2号的每分钟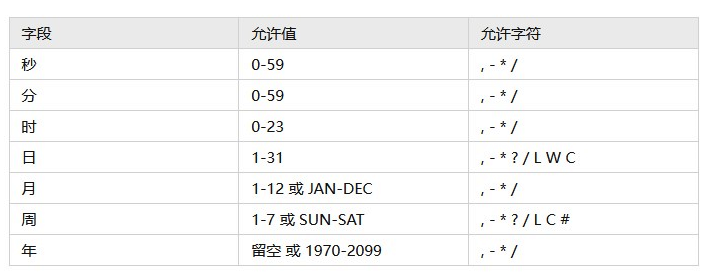
可参考:https://zhuanlan.zhihu.com/p/560949944?utm_id=0
19.bash中管道和重定向的作用
管道
command1 | command2 | command3...上面command1的(标准)输出会作为command2的(标准)输入,而command2的(标准)输出会作为command3的(标准)输入。由此各命令通过 【输出】 -> 【输入->输出】-> 【输入->输出】…的方式实现级联。
输出重定向(覆盖,追加)
正确输出: 1> 1>> 等价于 > >>
错误输出: 2> 2>>
输入重定向
标准输入: < 等价 0<
20.日志切割相关知识点
如果没有日志轮转,日志文件会越来越大
将丢弃系统中最旧的日志文件,以节省空间
logrotate本身不是系统守护进程,它是通过计划任务crond每天执行
日志轮转状态/var/lib/logrotate/logrotate.status
日志轮转规则按照/etc/logrotate.conf
21.cpu使用率会超过100%嘛,为什么
会。
在Linux系统中, CPU使用率通常是以百分比来衡量的,每个CPU核心的使用率上限为100%。但是,当系统执行高负载而且多线程应用程序时, CPU使用率就可能会超过100%。这是由于Linux在计算多个CPU核心的总使用率时,将所有核心的使用率相加,导致总使用率高于100%.例如,当一个应用程序使用了2个CPU核心,并且每个核心的使用率均达到了100%,那么系统的总CPU使用率将会是200%。这意味着,当一个应用程序使用多个CPU核心时,它可以使用超过100%的CPU使用率,这在Linux系统中是一个常见的现象。
理论上cpu总共有N个核,top查看的%CPU就可以显示到上限 N*100%。
22.进程运行级别,优先级如何计算
nice命令用来修改程序的优先级别,如果未指定程序,则会显示目前程序的优先级别,默认的nice值为0,范围为 -20(最高优先级别)到 19(最低优先级别)。
nice数字越小,表示程序会越优先被处理,在系统运行缓慢的时候,nice值越小的进程会有越高的优先处理级别
23.shell和其他语言有什么区别
Shell 是一个用 C 语言编写的程序,它是用户使用 Linux 的桥梁。Shell 既是一种命令语言,又是一
种程序设计语言。
Shell 是指一种应用程序,这个应用程序提供了一个界面,用户通过这个界面访问操作系统内核的
服务。(翻译官,帮你翻译命令给内核执行)。
shell是一种解释型语言,在脚本里面,如果有一步执行出现错误,后面的不受影响会继续执行。
shell使用变量需要加$符号。
24.如何查看系统负载
Linux的负载高,主要是由于CPU使用、内存使用、IO消耗三部分构成。任意一项使用过多,都将导致服务器负载的急剧攀升。
使用 top 查看进程的 CPU 负载
交互模式快捷键
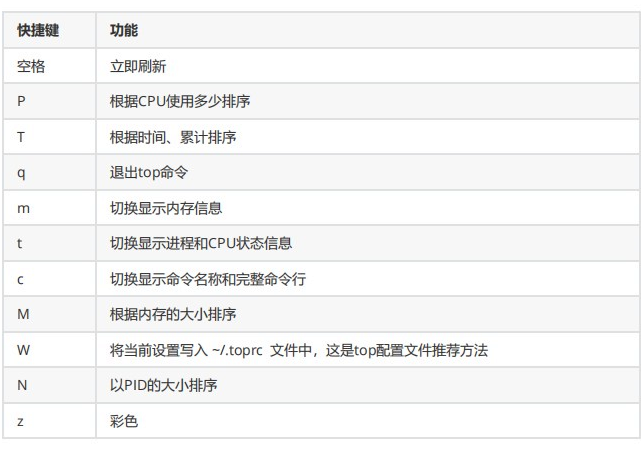
25.什么是内核态什么是用户态
内核态:处于内核态的 CPU 可以访问任意的数据,包括外围设备,比如网卡、硬盘等,处于内核态的 CPU 可以从一个程序切换到另外一个程序,并且占用 CPU 不会发生抢占情况,一般处于特权级 0 的状态我们称之为内核态。
用户态:处于用户态的 CPU 只能访问受限资源,不能直接访问内存等硬件设备,不能直接访问内存等硬件设备,必须通过「系统调用」陷入到内核中,才能访问这些特权资源。
26.有一块新硬盘,如何挂载
[root@localhost ~]# parted /dev/sdb mkpart primary 1 200M
[root@localhost ~]# mkfs.ext4 /dev/sdb1
[root@localhost ~]# vim /etc/fstab
/dev/sdb1 /mnt/volume1 ext4 defaults 0 0
[root@localhost ~]# mount -a