

1. 为什么要使用监控
- 故障检测和故障排除:监控可以帮助您快速发现系统故障或问题,并采取行动来解决它们,最小化系统的停机时间。
- 性能评估:通过监控关键指标,您可以了解系统的性能、资源使用情况和瓶颈,以便在必要时进行优化和扩展。
- 安全性:监控可以帮助您及早发现安全漏洞,异常动态或可疑活动,并采取措施进行保护。
- 规划和预测:通过收集历史数据和趋势分析,监控可以帮助您制定规划,并预测未来对资源的需求。
- 符合性和报告:监控可以帮助您满足监管要求,并生成报告以展示系统的运行状况和合规性。
2. 使用过哪些监控
- Zabbix:另一款流行的开源网络监控和告警系统,提供广泛的监控功能包括服务器、网络、数据库、应用程序等。
- Prometheus:一个开源的时间序列数据库和监控系统,被广泛用于云原生环境中的监控,支持灵活的指标收集和警报功能。
3. zabbix有哪些组件,各个组件的用处
- Zabbix Server:Zabbix系统的核心组件,负责接收和处理来自Zabbix代理程序、数据库和其他组件的监控数据,并提供用户界面进行配置和管理。
- Zabbix Proxy:可选的组件,用于分布式监控环境中的数据收集和缓存,减轻Zabbix Server的负载。
- Zabbix Agent:运行在被监控的主机上,负责采集主机的性能指标,例如CPU利用率、内存使用量、磁盘空间等,并将数据发送到Zabbix Server。
- Zabbix Web Interface:用户界面,提供用户配置、管理和监控Zabbix系统的功能,包括仪表板、报表和警报管理。
- Zabbix Database:通常使用MySQL,存储Zabbix系统的配置、历史性能数据、审计日志和其他相关信息。
4. zabbix如何采集数据
- 通过Zabbix被监控设备代理(agent)采集数据
- 在被监控设置安装并运行zabbix被监控设备代理进程(Zabbix系统自带的一个组件。在编译配置选项带--enable-agent选项。)通过该进程收集监控项目的数据,并与Zabbix服务器或监控服务器代理(Proxy)通信,主动发送或被动接受服务器或服务器代理查询的数据采集方式。这种方法只适用于采集服务器或工作站上的监控数据,不适合采集路由器、交换机、防火墙等网络设备的监控数据。
- 通过SNMP协议采集数据
- 即通过SNMP的查询和陷入进行监控数据的采集。适合对网络设备,如防火墙、交换机、路由器等的监控数据的采集。目前Zabbix系统支持SNMP v1 SNMP v2c和SNMP v3版本的协议。通过SNMP协议采集数据不需要在被监控设备上安装任何第三方软件,但是需要配置和开启SNMP服务,并允许监控服务器查询。这个是我们目前使用比较多的数据采集方法。缺点是,其通信协议走的UDP协议,传输为不可靠传输,所以存在丢数据的现象。同时,MIB库一般是跟被监控设备有关,不适合监控自定义的项目。
- 简单检查
- 这种数据采集方法是指Zabbix服务器(也包括服务器代理)自身通过检查被监控设备的tcp端口状态或ICMP的信息来获取监控数据的数据采集方法。不需要在被监控设备上安装任何第三方软件。但是,这种方法只适合收集像服务的端口状态等状态数据,不适合采集性能方面的数据。
- Zabbix系统内部数据采集
- Zabbix系统内部数据采集方法就是采集和监控Zabbix系统自身状态和性能数据的方法。Zabbix系统内部数据采集方法是由Zabbix服务器端通过计算获取的,所以这种数据采集方法不需要安装任何的客户端。这个数据采集方法只适用于Zabbix服务器自身的监控,不适用其它设备和主机。主要用于监控Zabbix系统自身的问题。
其余种类参考博客:http://blog.chinaunix.net/uid-9411004-id-4115731.html
5. zabbix的主动模式和被动模式
zabbix监控方式
- 被动模式:
- 被动检测:相对于agent而言;agent, server向agent请求获取配置的各监控项相关的数据,
- agent接收请求、获取数据并响应给server
- 主动模式
- 主动检测:相对于agent而言;agent(active),agent向server请求与自己相关监控项配置,主动地将server配置的监控项相关的数据发送给server
- 主动监控能极大节约监控server 的资源
6. zabbix监控项,监控指标,怎么持久化
- Zabbix Database:默认情况下,Zabbix使用关系型数据库(如MySQL、PostgreSQL)来存储监控项数据、配置信息和历史数据。监控项数据会持久保存在数据库中,并可用于生成图表、生成报表和进行趋势分析。
- 数据存档:Zabbix支持数据存档功能,可以将监控项的历史数据和告警数据存档到磁盘上的数据文件中。这可以帮助减少数据库存储压力,并保留长期的监控数据,以便日后查看。
- 数据库分区:Zabbix还支持在数据库中进行数据分区,可将历史数据按照时间范围划分为不同的分区。这可以提高查询性能和数据访问效率,并简化了数据保留和管理。
7. zabbix告警
- 触发器:在Zabbix中,告警是由触发器引发的。触发器是一种根据监控项的数值或状态来确定问题是否存在的机制。如果满足了触发器定义的条件,该触发器将引发一个告警。
- 告警方式:Zabbix可以通过多种方式进行告警通知,包括电子邮件、短信、扩展信息等。您可以为每个触发器配置多种不同的通知方式。
- 灵活的配置:Zabbix允许您灵活地配置告警触发条件,可以基于监控项的数值、持续时间、以及其他条件来定义触发器。
- 自定义动作:您可以创建自定义动作,以定义触发器触发时将采取的操作,例如发送通知、运行脚本、或者自动执行一些修复操作。
- 维护期:Zabbix还支持定义维护期,可以在维护期间禁用或减少触发器的通知,以避免因维护操作而引发过多的无关告警。
- 多级别告警:Zabbix可以根据触发条件的严重程度定义多个不同级别的告警,以便根据问题的重要性采取不同的通知和修复行动。
8. snmp的作用与使用的端口号
在Zabbix中,SNMP(Simple Network Management Protocol,简单网络管理协议)常用于获取网络设备(如交换机、路由器、防火墙等)的监控数据。它可以通过SNMP协议从这些网络设备中获取系统状态、接口流量、CPU利用率等信息,从而帮助管理员有效地监控和管理网络设备。
在Zabbix中,SNMP的主要作用包括:
- 监控网络设备:通过SNMP协议,Zabbix可以实时监控网络设备的健康状态、性能和运行情况。
- 故障检测:Zabbix可以利用SNMP获取的数据来进行故障检测,及时发现设备的异常状态并进行相应的告警和处理。
- 性能分析:通过收集网络设备的SNMP数据,Zabbix可以进行性能分析,帮助识别瓶颈并对网络设备进行优化。
SNMP在Zabbix中的使用流程包括:
- 在Zabbix中配置SNMP监控项,以定义需要从网络设备中收集的数据。
- 确保网络设备已启用SNMP服务,并配置了Zabbix Server的IP地址为允许的SNMP管理站点。
- 在Zabbix中配置网络设备的SNMP连接信息,如IP地址、SNMP团体字和版本等。
- 让Zabbix Server定期从网络设备上通过SNMP获取数据,并将其存储到数据库中进行进一步的分析和处理。
关于端口号,SNMP协议使用的端口号为UDP 161和UDP 162:
- UDP 161端口:用于SNMP的管理信息。
- UDP 162端口:用于SNMP的Trap陷阱信息。
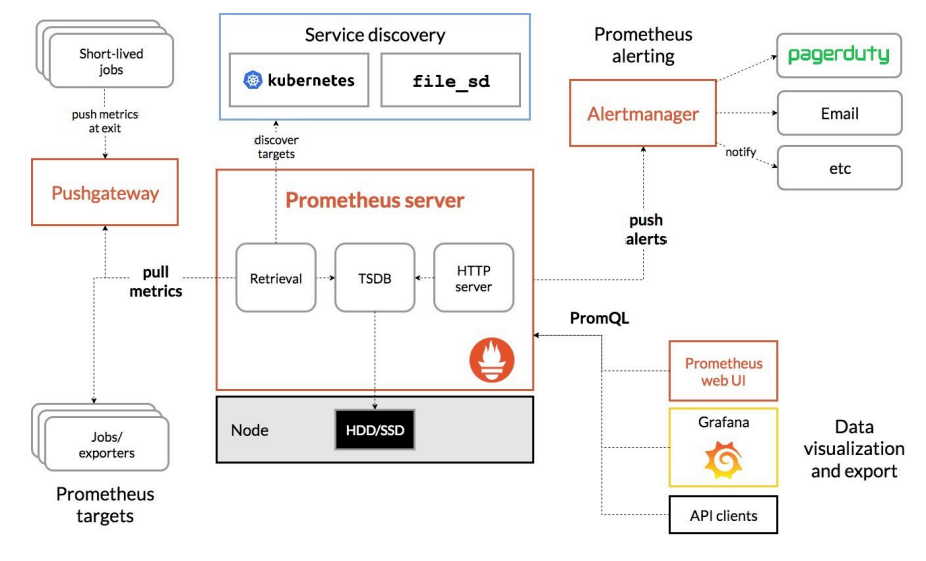
9. Prometheus的组件、架构
- Prometheus Server 直接从监控目标中或者间接通过推送网关来拉取监控指标,它在本地存储所有抓取到的样本数据,并对此数据执行一系列规则,以汇总和记录现有数据的新时间序列或生成告警。可以通过 Grafana或者其他工具来实现监控数据的可视化。
- Prometheus server是Prometheus架构中的核心组件,基于go语言编写而成,无第三方依赖关系,可以独立部署在物理服务器上、云主机、Docker容器内。主要用于收集每个目标数据,并存储为时间序列数据,对外可提供数据查询支持和告警规则配置管理。
- Prometheus服务器可以对监控目标进行静态配置管理或者动态配置管理,它将监控采集到的数据按照时间序列存储在本地磁盘的时序数据库中(当然也支持远程存储),自身对外提供了自定义的PromQL语言,可以对数据进行查询和分析
- Client Library是用于检测应用程序代码的客户端库。在监控服务之前,需要向客户端库代码添加检测实现Prometheus中metric的类型。
- Exporter(数据采集)用于输出被监控组件信息的HTTP接口统称为Exporter(导出器)。目前互联网公司常用的组件大部分都有Expoter供直接使用,比如Nginx、MySQL、linux系统信息等。
- Pushgateway是指用于支持短期临时或批量计划任务工作的汇聚节点。主要用于短期的job,此类存在的job时间较短,可能在Prometheus来pull之前就自动消失了。所以针对这类job,设计成可以直接向Pushgateway推送metric,这样Prometheus服务器端便可以定时去Pushgateway拉去metric
- Pushgateway是prometheus的一个组件,prometheus server默认是通过exporter主动获取数据(默认采取pull拉取数据),pushgateway则是通过被动方式推送数据到prometheus server,用户可以写一些自定义的监控脚本把需要监控的数据发送给pushgateway, 然后pushgateway再把数据发送给Prometheus server
- 总结就是pushgateway是普罗米修斯的一个组件,是通过被动的方式将数据上传至普罗米修斯。这个可以解决不在一个网段的问题
- Alertmanager主要用于处理Prometheus服务器端发送的alerts信息,对其去除重数据、分组并路由到正确的接收方式,发出告警,支持丰富的告警方式。
- Service Discovery:动态发现待监控的target,从而完成监控配置的重要组件,在容器环境中尤为重要,该组件目前由Prometheus Server内建支持
Prometheus 的整体架构以及生态系统组件如下图所示:
10. Prometheus如何采集数据
- 通过Pull方式采集数据:Prometheus使用HTTP协议定时从配置的数据源(例如应用程序、服务、操作系统)拉取数据。配置的数据源需要提供一个HTTP接口(/metrics)来暴露数据。Prometheus定期发起HTTP请求,拉取暴露的指标数据。这种方式适用于大多数应用程序和服务的监控。
- 通过Pushgateway进行推送:对于短周期的任务运行情况或者临时性的任务,Promethues提供了Pushgateway组件用于数据的推送。任务在执行完毕后将指标数据推送至Pushgateway,而Prometheus则从Pushgateway进行数据的拉取。
总的来说,Prometheus通过Pull方式及Pushgateway推送的方式来采集数据。采集的数据存储在Prometheus的时间序列数据库中,然后可以通过PromQL等方式进行查询、分析和展示。
11. Prometheus 的局限
- 长期存储:Prometheus的存储是基于本地磁盘的,这可能会限制其长期存储大量数据的能力。对于长期存储需求,特别是大量历史数据的情况,Prometheus可能不太适用。
- 跨数据中心支持:Prometheus本身的设计并不支持在分布式数据中心或多地区部署时有效地跨数据中心获取和整合监控数据。
- 数据复制和高可用性:Prometheus在集群和高可用方面的支持并不像一些分布式数据存储系统那样强大。
- Security Model:Prometheus的安全模型相对基本,例如在跨不同信任边界的系统之间的认证和加密传输支持相对有限。
- 大规模部署:在处理大型监控环境的时候,Prometheus可能需要处理大量的数据以及更大规模的元数据,这可能会导致性能和扩展性方面的一些挑战。
- 复杂查询:Prometheus的查询语言PromQL是功能强大的,但对于某些大规模和复杂的查询,可能需要更复杂的分析和处理。
12. Prometheus有哪些指标类型
- 计数器(Counter):代表一个单调递增的数值,通常用于表示增量,比如请求数、错误数等。
- 仪表盘(Gauge):代表一种样本数据可以任意变化的指标,即可增可减能指标监控,通常用于像温度或者内存使用率。
- 尺度(Gauge):表示一个数值。与计数器不同,尺度的值可以增加也可以减小,如当前连接数、内存使用量等。
- 直方图(Histogram):用于度量数据的分布情况,通常用于统计请求响应时间等。
- 摘要(Summary):与直方图类似,用于度量数据的分布情况,但提供对数据的近似准确度。
13. prometheus数据如何展示和告警
- Grafana集成:Grafana是一个流行的数据可视化工具,它可以与Prometheus集成,用于创建漂亮的仪表盘和图表来展示Prometheus采集的数据。Grafana提供了丰富的图表和监控面板,可以帮助用户直观地展示Prometheus的监控数据。
- Prometheus表达式查询:Prometheus允许用户使用PromQL(Prometheus Query Language)查询语言来对采集的数据进行灵活的查询和分析,并生成对应的图表和数据展示。
- AlertManager集成:Prometheus提供了一个名为AlertManager的组件,用于管理和处理告警。AlertManager可以与Prometheus集成,根据设定的触发条件和告警规则向运维人员发送告警通知,并提供了一些灵活的告警处理机制,如静默通知、抑制重复告警和故障转移等功能。
- Prometheus Web UI:Prometheus本身提供了一个基本的Web UI,可以用于查询和展示Prometheus采集的数据,也可以用于查看当前的告警状态。
14. prometheus和zabbix的区别
- 数据存储方式:
- Prometheus使用基于本地磁盘的时间序列数据库来存储数据。
- Zabbix使用关系型数据库(如MySQL)来存储监控数据。
- 数据采集方式:
- Prometheus使用pull模型,定期从应用程序和设备中拉取监控指标数据。
- Zabbix使用agent-based模型,其中代理程序主动连接到Zabbix服务器并发送数据。
- 监控数据模型:
- Prometheus在数据模型方面更加灵活,可以处理不同维度的标签化时间序列数据。
- Zabbix使用传统的监控项和触发器模型,采用模板定义和监控项配置来处理数据。
- 度量方式:
- Prometheus采用直接抓取指标数据的方式,灵活性更高,适用于微服务架构。
- Zabbix更适用于传统的服务器和网络设备的监控,具有更强大的监控项配置功能。
- 告警管理:
- Prometheus自带了AlertManager用于处理告警,并且支持更灵活的告警规则配置和处理。
- Zabbix内置了灵活的告警规则和动作,可以通过定义触发器和操作进行告警管理。
- 生态系统:
- Zabbix有更丰富的插件和集成支持,可以扩展到更多的系统和云服务。
- Prometheus生态系统更加专注于云原生应用的监控和管理,得益于Kubernetes和容器技术的广泛应用。