

1. 关系型和非关系型数据库的区别
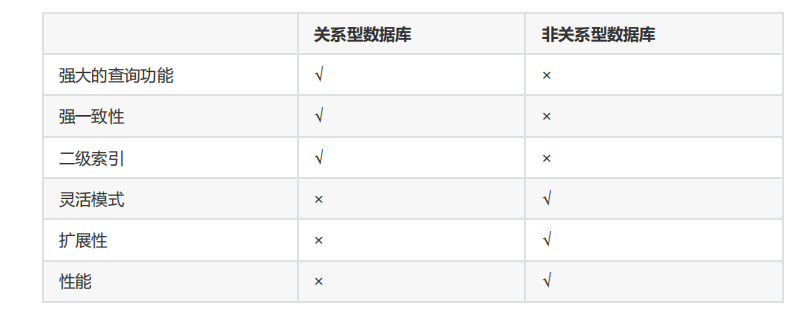
关系型数据库和非关系型数据库(NoSQL数据库)的主要区别在于数据组织、数据模型、扩展性、数据一致性和查询语言等方面。
- 数据组织。关系型数据库使用表格的形式来组织数据,每个表格包含行和列,每行代表一个数据项,每列代表数据项的属性;非关系型数据库使用不同的结构来组织数据,例如键-值对、文档、图形等。
- 数据模型。关系型数据库使用结构化数据模型,每个表格都有一个定义好的结构;非关系型数据库使用非结构化或半结构化的数据模型,数据项的结构可以在运行时动态定义。
- 扩展性。关系型数据库在水平方向上扩展性有限,因为表格之间的关系需要保持一致;非关系型数据库通常可以在水平方向上更轻松地扩展,因为数据项之间的关系不需要保持一致。
- 数据一致性。关系型数据库通常支持ACID事务,可以确保数据的一致性和完整性;非关系型数据库通常没有支持ACID事务,但提供较高的可扩展性和灵活性。
- 查询语言。关系型数据库使用结构化查询语言(SQL)进行查询和操作数据;非关系型数据库通常使用不同的查询语言或API,例如MongoDB使用JavaScript的查询语言。
此外,关系型数据库与非关系型数据库并非对立而是互补的关系,即通常情况下使用关系型数据库,在适合使用非关系型数据库的时候使用非关系型数据库,让非关系型数据库对关系型数据库的不足进行弥补。
2. 登录数据库的方式,如何远程登录
mysql
- -u:指定用户
- -p:指定密码
- -h:指定主机
- -P:指定端口
- -S:指定sock
- -e:指定SQL
- -D:指定的数据库名
实现数据库远程登录
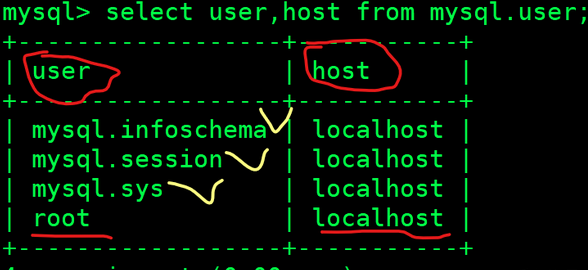
更新 mysql 数据库里的 user 表, 设置表里的 host 为 ' % '
mysql> update mysql.user set host='%' where user='root';
mysql> flush privileges;
mysql> select user,host from mysql.user;
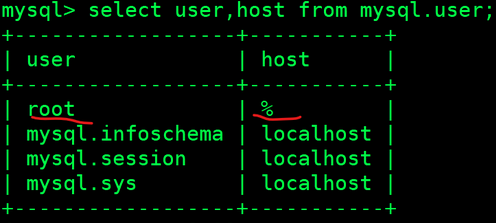
修改后任意IP都可以使用root用户进行远程登录了
3. MySQL的服务结构,当客户端发起请求后,处理过程
mysqld服务结构
实例=mysqld后台守护进程+Master Thread +干活的Thread+预分配的内存
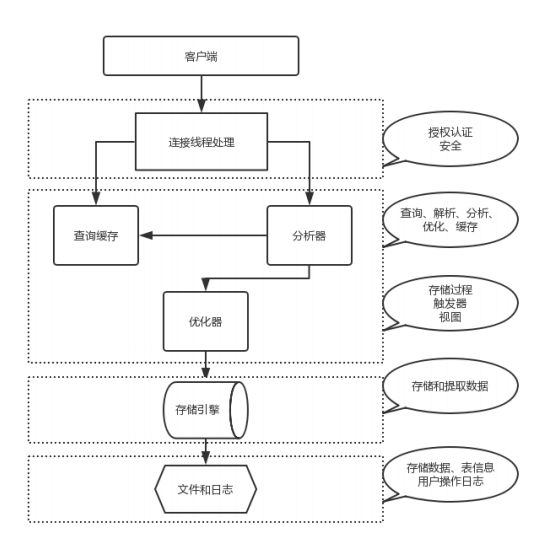
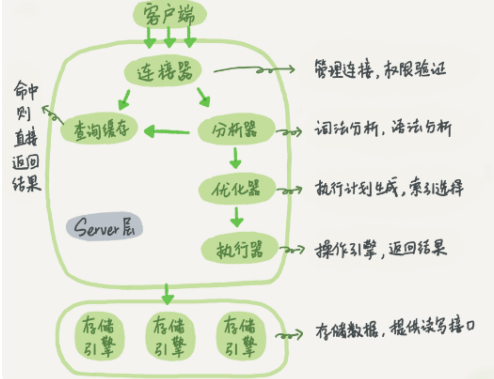
连接层
- 验证用户的合法性(ip,端口,用户名)
- 提供两种连接方式(socket,TCP/IP)
- 验证操作权限
- 提供一个与SQL层交互的专用线程
SQL层
- 接受连接层传来的SQL语句
- 检查语法
- 检查语义(DDL,DML,DQL,DCL)
- 解析器,解析SQL语句,生成多种执行计划
- 优化器,根据多种执行计划,选择最优方式
- 执行器,执行优化器传来的最优方式SQL
- 提供与存储引擎交互的线程
- 接收返回数据,优化成表的形式返回SQL
- 将数据存入缓存
- 记录日志,binlog
存储引擎
- 接收上层的执行结构
- 取出磁盘文件和相应数据
- 返回给SQL层,结构化之后生成表格,由专用线程返回给客户端
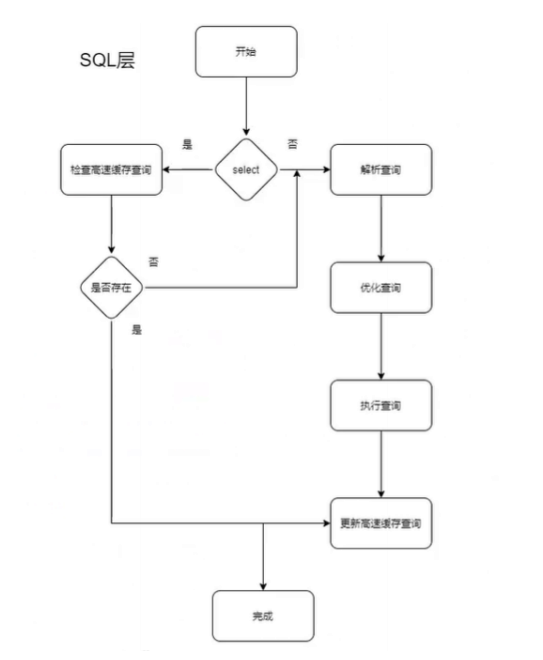
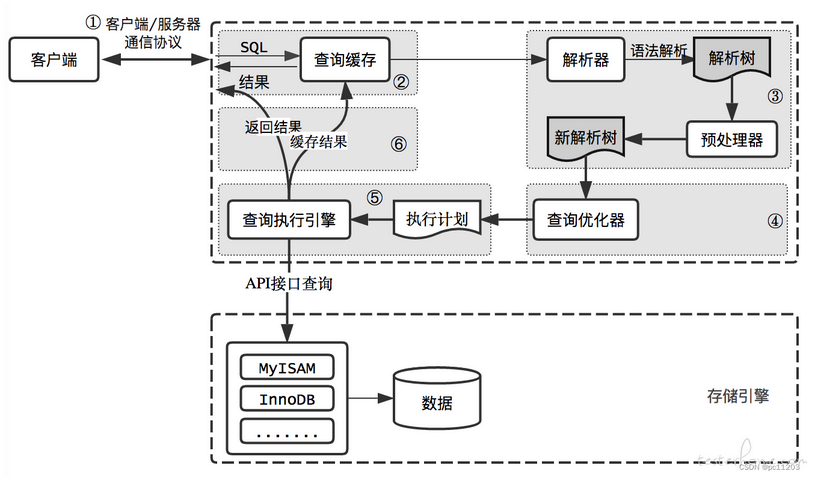
简述MySQL的执行流程
答:当客户端通过TCP协议与服务器连接时,MySQL服务器首先将客户端传输过来的主机地址、账号、密码等信息与mysql数据库下的user表中数据进行身份验证,若验证成功,则登录成功,若验证失败,则返回一条错误信息。
当客户端向服务器发送一次sql语句请求时,mysql服务器首先会经过解析器会sql语句进行解析,其中包含词法解析,语法解析等,解析完成后会生成一个语法树。经过解析器解析完成后,要经过优化器对语法树进行优化,最终生成一个优化器认为执行成本最低的执行计划,最终到达执行器,执行器会检查该用户的是否拥有权限等,最后调用存储引擎的API与缓冲池或磁盘交互,最终将查询返回结果给用户。
4. 如何设置或者重置MySQL密码
mysql -u root -p 123456
ALTER USER 'username'@'localhost' IDENTIFIED BY 'new_password';
#其中 'username' 是需要更新密码的用户名,'localhost' 表示只能从本地连接;'new_password' 是想要设置的新密码。
SET PASSWORD FOR 'username'@'localhost' = '';
#将密码重置为空字符串
忘记了MySQL的root密码或者任何其他用户的密码
停止MySQL服务。
systemctl stop mysqld
# 或者
/etc/init.d/mysql stop以不检查权限的方式启动MySQL服务。这样你可以在不输入密码的情况下登录到MySQL:
mysqld_safe --skip-grant-tables &登录到MySQL
mysql -u root
在MySQL提示符下,运行以下SQL语句来重置root用户的密码
USE mysql;
UPDATE user SET authentication_string=PASSWORD('new_password') WHERE User='root';
FLUSH PRIVILEGES;
EXIT;
#注意:在MySQL 5.7及更高版本中,PASSWORD()函数已被弃用,应该使用以下命令:
ALTER USER 'root'@'localhost' IDENTIFIED BY 'new_password';
FLUSH PRIVILEGES;
EXIT;停止当前的mysqld_safe进程
killall mysqld正常启动MySQL服务
systemctl start mysqld
# 或者
/etc/init.d/mysql start5. DDL,DML,DQL,DCL等SQL语句的写法
参考博客:
6. select的高级用法
同上
7.什么是索引,索引的作用,索引的种类
索引:对数据库中一列或多列的值进行排序的一种结构
作用:使用索引可以快速访问数据库表中特定信息(加速检索表中的数据)
索引的种类
- BTree索引:这是MySQL的默认索引类型,适用于所有存储引擎。BTree索引是一种平衡树结构,支持等值查找、范围查找和排序,适用于大部分情况。
- 哈希索引:哈希索引是基于哈希表实现的,只能进行等值查找,不能用于排序操作。适用于Memory存储引擎。
- 全文索引:用于全文搜索的索引类型,适用于MyISAM和InnoDB存储引擎。
- 空间索引:用于地理空间数据类型的索引类型,适用于MyISAM和InnoDB存储引擎。
- 前缀索引:可以为索引的列指定前缀长度,以节约索引空间。适用于BTree和哈希索引。
- 复合索引:指对表中的多个列进行索引,适用于BTree和哈希索引。
8.b树和b+树的区别
B树和B+树是两种不同的数据结构,它们主要用于文件系统和数据库系统中,以提高数据检索的效率。以下是B树和B+树的主要区别:
- 数据存储位置。B树中,数据可以存储在节点的叶子和非叶子节点上,而B+树中,所有数据都存储在叶子节点上,非叶子节点仅用于索引。
- 数据检索效率。B树中,数据检索效率与数据在树中的位置有关,在根节点时,检索效率为最小,在叶节点时,检索效率为最大。B+树中,所有数据检索的效率是固定的,因为所有数据都在叶子节点中,且叶子节点通过双向链表连接。
- 数据更新操作。B树中,数据更新操作可能会导致树的高度发生变化,从而影响检索效率。B+树中,由于所有数据更新都在叶子节点进行,因此对树结构的影响较小。
- 磁盘读写效率。B+树的内部节点不保存数据,只包含索引信息,这使得每个内部节点的存储容量更大,从而提高了磁盘读写效率。
- 数据遍历效率。B+树更适合于范围查询,因为它只需要遍历叶子节点链表即可,而B树需要进行重复的中序遍历来检索数据。
综上所述,B+树在数据检索效率、磁盘读写效率和数据遍历效率方面通常优于B树。
9.什么情况下会导致索引失效
- 对索引列进行计算或使用函数。例如,如果查询语句中使用了函数或表达式,例如所有的人“一二二一”,或者对索引列进行函数操作。
- 使用不匹配的数据类型。例如,如果查询语句中使用的数据类型与索引列的数据类型不匹配,也会导致索引失效。
- 使用不正确的查询条件。例如,在WHERE中使用OR时,如果有一个列没有索引,那么其它列的索引将不起作用。
- 使用反向操作。例如,使用了link操作,索引就将不起作用。
- 使用不正确的字符串查询。例如,字符串查询没有使用单引号包裹,或者在like查询中以%开头。
- 使用不正确的联合索引。例如,违反了最左前缀法则,跳过某一列查询都会导致索引失效。
- 数据量太小。如果表中数据量太小可能会放弃使用索引,直接进行全表扫描。
- 索引字段类型不匹配。例如,对于性别列,如果只有两种取值,用索引查询时只能使用全表扫描。
- 查询条件不稳定。如果查询条件中包含变量或函数,查询条件会在运行时才确定,无法在编译时确定索引的使用情况。
- 数据分布不均匀。例如,对于性别列,如果只有两种取值,用索引查询时只能使用全表扫描。
- 使用内部函数。例如,使用oracle内部函数会导致索引失效。
10.MySQL的explain
EXPLAIN关键字可以模拟查询优化器执行SQL语句,从而分析出SELECT语句的执行逻辑,帮助我们排查SQL语句的性能问题点,更有效的利用索引来优化SQL语句。
参考博客:https://zhuanlan.zhihu.com/p/333350978
11.什么是事务,事务的作用
事务是数据库管理系统中的一个概念,用于管理一组数据库操作,使它们作为一个不可分割的工作单元,要么全部执行成功,要么全部回滚(撤销)。事务确保数据库的一致性和完整性,并且可以恢复到之前的状态,以防止发生错误或意外情况。
事务的作用包括:
- 保证数据的一致性: 事务必须使数据库从一个一致性状态变换到另外一个一致性状态。
- 确保数据的完整性: 事务通过ACID属性(原子性、一致性、隔离性和持久性)来确保数据的完整性,防止数据丢失或损坏。
- 提供隔离性: 事务的隔离性确保了多个并发事务之间的隔离,避免了数据交叉访问和干扰,保证了每个事务的独立性。
- 支持原子性: 事务要么全部执行成功,要么全部回滚,这种原子性确保了事务的完整性。
- 支持持久性: 一旦事务被提交,其对数据库的更改就会持久保存,即使系统崩溃也不会丢失。
12.事务的ACID分别怎么体现
1.1 原子性(Atomic)
- 原子性是指事务是一个不可分割的工作单位,事务中的操作要么全部成功,要么全部失败。比如在同一个事务中的SQL语句,要么全部执行成功,要么全部执行失败。
1.2 一致性(Consistent)
- 官网上事务一致性的概念是:事务必须使数据库从一个一致性状态变换到另外一个一致性状态。
- 换一种方式理解就是:事务按照预期生效,数据的状态是预期的状态。
- 举例说明:张三向李四转100元,转账前和转账后的数据是正确的状态,这就叫一致性,如果出现张三转出100元,李四账号没有增加100元这就出现了数据错误,就没有达到一致性。
1.3 隔离性(Isolated)
- 事务的隔离性是多个用户并发访问数据库时,数据库为每一个用户开启的事务,不能被其他事务的操作数据所干扰,多个并发事务之间要相互隔离。
1.4 持久性(Durable)
- 持久性是指一个事务一旦被提交,它对数据库中数据的改变就是永久性的,接下来即使数据库发生故障也不应该对其有任何影响。
- 例如我们在使用JDBC操作数据库时,在提交事务方法后,提示用户事务操作完成,当我们程序执行完成直到看到提示后,就可以认定事务以及正确提交,即使这时候数据库出现了问题,也必须要将我们的事务完全执行完成,否则就会造成我们看到提示事务处理完毕,但是数据库因为故障而没有执行事务的重大错误。
13.事务的隔离级别
事务的隔离级别是衡量并发控制能力的一个重要指标,它定义了多个事务之间数据可见性的规则。常见的隔离级别包括:
- 读未提交(Read Uncommitted)。允许脏读,即一个事务读取到另一个事务未提交的数据。但这种级别下,事务B更新了数据并提交,事务A再次读取该数据时,数据可能已经发生了改变,导致不可重复读。
- 读已提交(Read Committed)。解决了脏读问题,但可能出现不可重复读。事务A读取了数据,事务B更新了数据并提交,事务A再次读取该数据时,数据可能已经发生了改变。
- 可重复读(Repeatable Read)。解决了脏读和不可重复读问题,但可能出现幻读。对正在操作的数据加锁,确保事务内多次读取相同数据时,结果是一致的。但无法防止其他事务提交新数据,导致事务内统计结果不一致。
- 串行化(Serializable)。最高的隔离级别,所有事务串行执行,保证数据的一致性和完整性,但并发性较差。
14.脏读,幻读,不可重复读
1.脏读:
- 脏读是指一个事务在处理数据的过程中,读取到另一个未提交事务的数据。
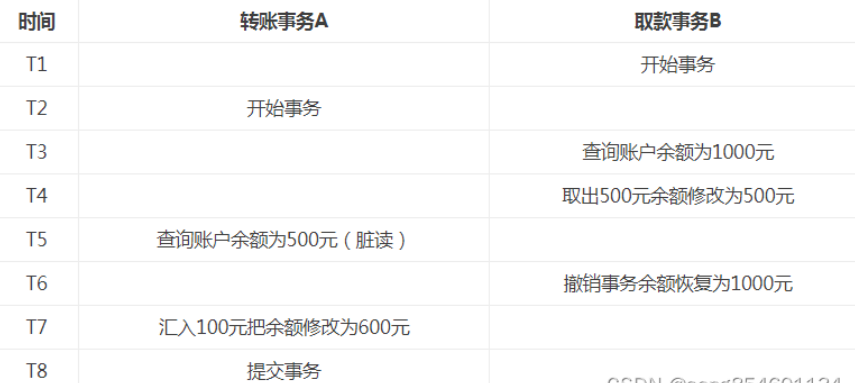
2.不可重复读:
- 不可重复读是指对于数据库中的某个数据,一个事务范围内的多次查询却返回了不同的结果,这是由于在查询过程中,数据被另外一个事务修改并提交了。
- 不可重复读和脏读的区别是,脏读读取到的是一个未提交的数据,而不可重复读读取到的是前一个事务已提交的数据。
- 而不可重复读在一些情况也并不影响数据的正确性,比如需要多次查询的数据也是要以最后一次查询到的数据为主。
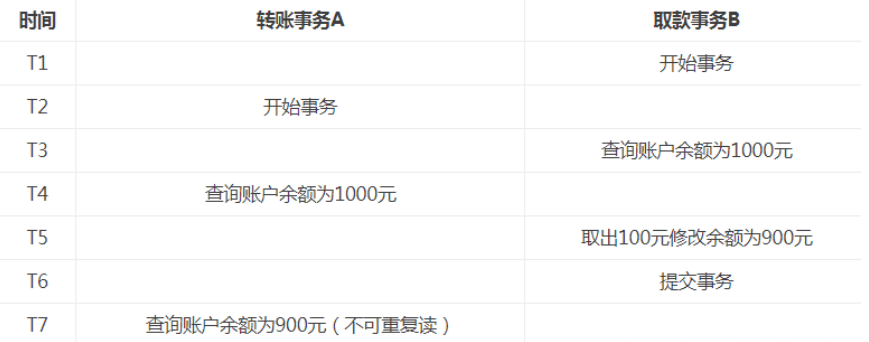
3.幻读:
- 幻读是事务非独立执行时发生的一种现象。例如事务T1对一个表中所有的行的某个数据项做了从“1”修改为“2”的操作,这时事务T2又对这个表中插入了一行数据项,
- 而这个数据项的数值还是为“1”并且提交给数据库。而操作事务T1的用户如果再查看刚刚修改的数据,会发现还有一行没有修改,其实这行是从事务T2中添加的,就好像产生幻觉一样,这就是发生了幻读。
- 幻读和不可重复读都是读取了另一条已经提交的事务(这点就脏读不同),所不同的是不可重复读查询的都是同一个数据项,而幻读针对的是一批数据整体(比如数据的个数)。
说法一:
事务 A 根据条件查询得到了 N 条数据,但此时事务 B 删除或者增加了 M 条符合事务 A 查询条件的数据,这样当事务 A 再次进行查询的时候真实的数据集已经发生了变化,但是A却查询不出来这种变化,因此产生了幻读。
说法二:
幻读并不是说两次读取获取的结果集不同,幻读侧重的方面是某一次的 select 操作得到的结果所表征的数据状态无法支撑后续的业务操作。更为具体一些:A事务select 某记录是否存在,结果为不存在,准备插入此记录,但执行 insert 时发现此记录已存在,无法插入,此时就发生了幻读。产生这样的原因是因为有另一个事务往表中插入了数据。
4、提醒
- 不可重复读的重点是修改:
- 同样的条件,你读取过的数据,再次读取出来发现值不一样了
- 幻读的重点在于新增或者删除:
- 同样的条件,第 1 次和第 2 次读出来的记录数不一样
15. 事务的锁
数据库中基本锁的种类:
排他锁(X锁)
- 排他锁也叫写锁。当事务T对数据对象A加上X锁时,就只允许事物T对A进行和修改A,其他事务都无法对A再加任何其他的锁,直到T释放对A的锁。
共享锁(S锁)
- 共享锁也叫读锁。当事务T对数据对象A加上S锁后,事务T可以读取A,但是不能对A进行修改,其他事务只能对A加上S锁,但是不能加X锁,直到T释放掉对A的S锁为止。
死锁和活锁
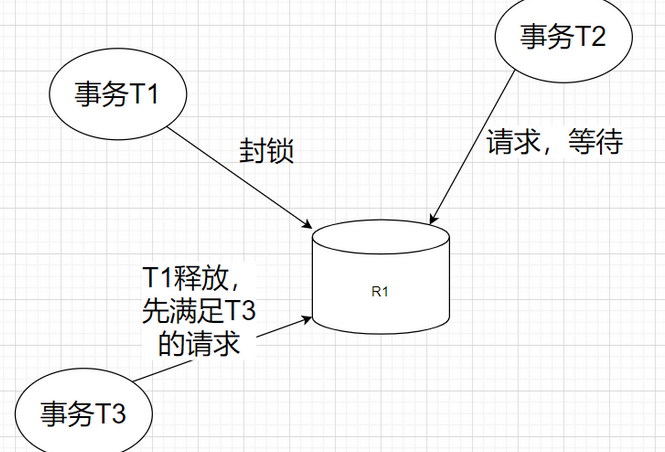
活锁
- 活锁就是一个事务在等待其他锁的释放,但是这个锁释放后先满足了其他事务的请求,事务T2就永远在等待。
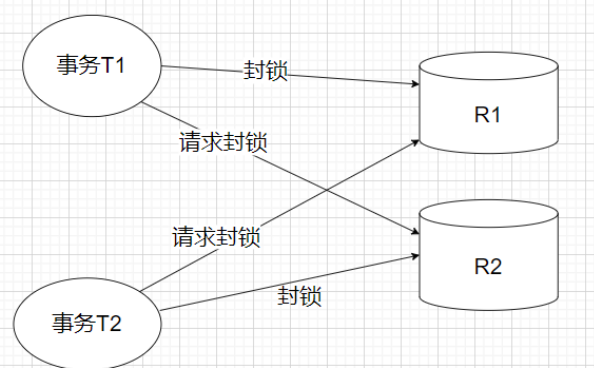
死锁
- 死锁就是一个事务T1先封锁一个数据对象R1,事务T2封锁了一个数据对象R2,这时事务T1又请求数据对象R2,而事务T2也请求数据对象R1,这样两个事务都在等对方先释放掉锁,两个事务就永远不会结束,形成死锁。
16. 悲观锁和乐观锁的区别
悲观锁和乐观锁是两种不同的并发控制策略,它们各自适用于不同的场景。
- 悲观锁(Pessimistic Lock)的核心理念是,在数据被访问或修改时,悲观锁会假设其他线程可能正在修改这些数据。因此,悲观锁在访问数据时会加锁,以确保数据不会被其他线程修改。当一个线程持有锁时,其他线程需要等待该锁被释放。
- 这种策略适用于写入操作频繁的场景,因为频繁的写入操作需要确保数据的一致性和完整性。然而,悲观锁的缺点在于,由于频繁加锁和解锁,可能会影响系统的吞吐量,尤其是在读取操作较多的情况下。
- 乐观锁(Optimistic Lock)的核心理念是,在数据被访问或修改时,乐观锁会假设其他线程不会修改这些数据。乐观锁在访问数据时不会加锁,而是在尝试更新数据时,通过比较数据的一致性来确保数据没有被其他线程修改。如果数据已经被其他线程修改,则更新操作会失败。
- 乐观锁适用于读取操作频繁的场景,因为它不需要频繁加锁,可以提高系统的并发性能。但是,如果数据在乐观锁尝试更新时已经被其他线程修改,那么需要重新获取数据并尝试更新,这会增加系统的复杂性和可能出现的错误。
总结来说,悲观锁和乐观锁各有优缺点,选择哪种锁取决于具体的业务场景和并发需求。如果写入操作频繁,适合使用悲观锁;如果读取操作频繁,适合使用乐观锁。
17. 事务redo和undo的区别和过程
事务的隔离性由 锁机制 实现。
事务的原子性、一致性和持久性由事务的 redo 日志和 undo 日志来保证。
REDO LOG 称为 重做日志 ,提供再写入操作,恢复提交事务修改的页操作,用来保证事务的持久性。
- 是存储引擎层(innodb)生成的日志, 记录的是" 物理级别 "上的页修改操作, 比如页号×××, 偏移量yyy, 写入了'zzz'数据. 主要为了保证数据的可靠性;
UNDO LOG 称为 回滚日志 ,回滚行记录到某个特定版本,用来保证事务的原子性、一致性。
- 是存储引擎层(innodb)生成的日志, 记录的是 逻辑操作 日志, 比如对某一行数据进行了INSERT语句操作, 那么undo log就记录一条与之相反的delete操作. 主要用于 事务的回滚 (undo log 记录的是每个修改操作的 逆操作 ) 和 一致性非锁定读 (undo log回滚行记录到某种特定的版本-- MVCC, 即多版本并发控制)
redolog的整体流程
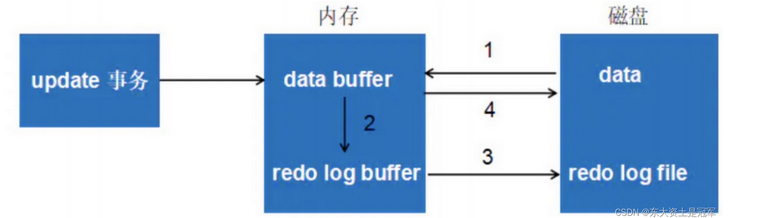
- 第 1 步:先将原始数据从磁盘中读入内存中来,修改数据的内存拷贝
- 第 2 步:生成一条重做日志并写入 redo log buffer ,记录的是数据被修改后的值
- 第 3 步:当事务 commit 时,将 redo log buffer 中的内容刷新到 redo log file ,对 redo log file 采用追加写的方式
- 第 4 步:定期将内存中修改的数据刷新到磁盘中
类比说明:
不知道你还记不记得《孔乙己》这篇文章,酒店掌柜有一个粉板,专门用来记录客人的赊账记录。如果赊账的人不多,那么他可以把顾客名和账目写在板上。但如果赊账的人多了,粉板总会有记不下的时候,这个时候掌柜一定还有一个专门记录赊账的账本。
如果有人要赊账或者还账的话,掌柜一般有两种做法:一种做法是直接把账本翻出来,把这次赊的账加上去或者扣除掉;另一种做法是先在粉板上记下这次的账,等打烊以后再把账本翻出来核算。
在生意红火柜台很忙时,掌柜一定会选择后者,因为前者操作实在是太麻烦了。首先,你得找到这个人的赊账总额那条记录。你想想,密密麻麻几十页,掌柜要找到那个名字,可能还得带上老花镜慢慢找,找到之后再拿出算盘计算,最后再将结果写回到账本上。
这整个过程想想都麻烦。相比之下,还是先在粉板上记一下方便。你想想,如果掌柜没有粉板的帮助,每次记账都得翻账本,效率是不是低得让人难以忍受?
同样,在 MySQL 里也有这个问题,如果每一次的更新操作都需要写进磁盘,然后磁盘也要找到对应的那条记录,然后再更新,整个过程 IO 成本、查找成本都很高。为了解决这个问题,MySQL 的设计者就用了类似酒店掌柜粉板的思路来提升更新效率。
而粉板和账本配合的整个过程,其实就是 MySQL 里经常说到的 WAL 技术,WAL 的全称是 Write-Ahead Logging,它的关键点就是先写日志,再写磁盘,也就是先写粉板,等不忙的时候再写账本。
具体来说,当有一条记录需要更新的时候,InnoDB 引擎就会先把记录写到 redo log(粉板)里面,并更新内存,这个时候更新就算完成了。同时,InnoDB 引擎会在适当的时候,将这个操作记录更新到磁盘里面,而这个更新往往是在系统比较空闲的时候做,这就像打烊以后掌柜做的事。
如果今天赊账的不多,掌柜可以等打烊后再整理。但如果某天赊账的特别多,粉板写满了,又怎么办呢?这个时候掌柜只好放下手中的活儿,把粉板中的一部分赊账记录更新到账本中,然后把这些记录从粉板上擦掉,为记新账腾出空间。
与此类似,InnoDB 的 redo log 是固定大小的,比如可以配置为一组 4 个文件,每个文件的大小是 1GB,那么这块“粉板”总共就可以记录 4GB 的操作。从头开始写,写到末尾就又回到开头循环写,如下面这个图所示。
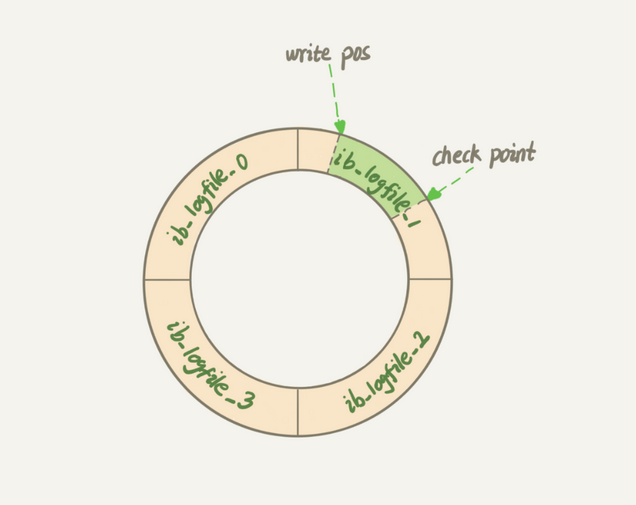
write pos 是当前记录的位置,一边写一边后移,写到第 3 号文件末尾后就回到 0 号文件开头。checkpoint 是当前要擦除的位置,也是往后推移并且循环的,擦除记录前要把记录更新到数据文件。
write pos 和 checkpoint 之间的是“粉板”上还空着的部分,可以用来记录新的操作。如果 write pos 追上 checkpoint,表示“粉板”满了,这时候不能再执行新的更新,得停下来先擦掉一些记录,把 checkpoint 推进一下。
有了 redo log,InnoDB 就可以保证即使数据库发生异常重启,之前提交的记录都不会丢失,这个能力称为 crash-safe。
要理解 crash-safe 这个概念,可以想想我们前面赊账记录的例子。只要赊账记录记在了粉板上或写在了账本上,之后即使掌柜忘记了,比如突然停业几天,恢复生意后依然可以通过账本和粉板上的数据明确赊账账目。
undolog的整体流程

当我们执行INSERT时:
begin ;
insert INTO user (name) values ( "tom" );
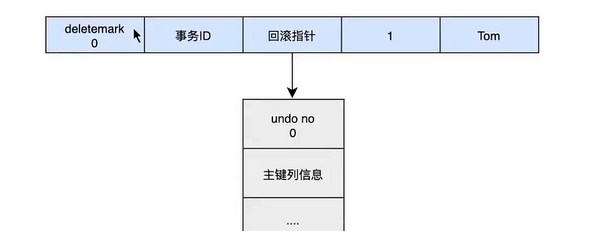
当我们执行UPDATE时:
对于更新得操作会产生update undo log ,并且会分更新主键和不更新主键的, 假设现在执行:
update user set name = "Sun" where id = 1;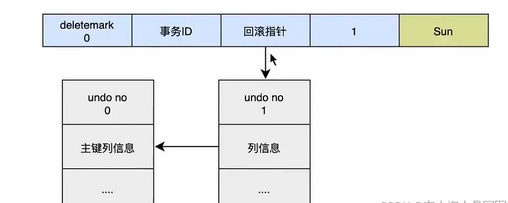
这时会把老的记录写入新的undo log, 让回滚指针指向新的undo log, 他的undo no是1, 并且新的undo log 会指向老的undo log(undo no = 0 )
假设现在执行:
update user set id = 2 where id = 1;
对于更新主键的操作, 会先把原来的数据deletemark标识打开, 这时并没有真正的删除数据, 真正的删除会交给清理线程去判断, 然后再后面插入一条新的数据, 新的数据也会产生undo log , 并且undo log 的序号会递增.
可以发现每次对数据的变更都会产生一个undo log, 当一条记录被变更多次时, 那么就会产生多条undo log, undo log记录的是变更前的日志, 并且每个undo log 的序号是递增的, 那么当要回滚的时候, 按照序号依次向前推, 就可以找到我们的原始数据了
undo log是如何回滚的
以上面的例子来说,假设执行 rollback ,那么对应的流程应该是这样:
- 通过 undo no=3 的日志把 id=2 的数据删除
- 通过 undo no=2 的日志把 id=1 的数据的 deletemark 还原成 0
- 通过 undo no=1 的日志把 id=1 的数据的 name 还原成 Tom
- 通过 undo no=0 的日志把 id=1 的数据删除
可参考博客:https://blog.csdn.net/weixin_47786582/article/details/132701284
18.在事务未提交的情况下,数据库服务器重启,会发生什么
事务开启时,事务中的操作,都会先写入存储引擎的日志缓冲中,在事务提交之前,这些缓冲的日志都需要提前刷新到磁盘上持久化,这就是人们口中常说的“日志先行”(Write-Ahead Logging)。
日志分为两种类型:redo log和undo log
(1)redo log
在系统启动的时候,就已经为redo log分配了一块连续的存储空间,以顺序追加的方式记录redo log,通过顺序io来改善性能。所有的事务共享redo log的存储空间,它们的redo log按语句的执行顺序,依次交替的记录在一起。如下一个简单示例:
记录1:<trx1, insert...>
记录2:<trx2, delete...>
记录3:<trx3, update...>
记录4:<trx1, update...>
记录5:<trx3, insert...>
此时如果数据库崩溃或者宕机,那么当系统重启进行恢复时,就可以根据redo log中记录的日志,把数据库恢复到崩溃前的一个状态。未完成的事务,可以继续提交,也可以选择回滚,这基于恢复的策略而定。
(2)undo log
undo log主要为事务的回滚服务。在事务执行的过程中,除了记录redo log,还会记录一定量的undo log。undo log记录了数据在每个操作前的状态,如果事务执行过程中需要回滚,就可以根据undo log进行回滚操作。单个事务的回滚,只会回滚当前事务做的操作,并不会影响到其他的事务做的操作。
以下是undo+redo事务的简化过程,假设有2个数值,分别为A和B,值为1,2
- start transaction;
- 记录 A=1 到undo log;
- update A = 3;
- 记录 A=3 到redo log;
- 记录 B=2 到undo log;
- update B = 4;
- 记录B = 4 到redo log;
- 将redo log刷新到磁盘
- commit
在1-8的任意一步系统宕机,事务未提交,该事务就不会对磁盘上的数据做任何影响。如果在8-9之间宕机,恢复之后可以选择回滚,也可以选择继续完成事务提交,因为此时redo log已经持久化。若在9之后系统宕机,内存映射中变更的数据还来不及刷回磁盘,那么系统恢复之后,可以根据redo log把数据刷回磁盘。所以,redo log其实保障的是事务的持久性,而undo log则保障了事务的原子性、一致性。
19.什么是MySQL的存储引擎
存储引擎简介
- MySQL中的数据用各种不同的技术存储在文件(或者内存)中。这些技术中的每一种技术都使用不同的存储机制、索引技巧、锁定水平并且最终提供广泛的不同的功能和能力。通过选择不同的技术,你能够获得额外的速度或者功能,从而改善你的应用的整体功能。
- 例如,如果你在研究大量的临时数据,你也许需要使用内存存储引擎。内存存储引擎能够在内存中存储所有的表格数据。又或者,你也许需要一个支持事务处理的数据库(以确保事务处理不成功时数据的回退能力)。
- 这些不同的技术以及配套的相关功能在MySQL中被称作存储引擎(也称作表类型)。
MySQL自带的存储引擎类型
- MySQL 提供以下存储引擎:
- InnoDB
- MyISAM
- MEMORY
- ARCHIVE
- FEDERATED
- EXAMPLE
- BLACKHOLE
- MERGE
- NDBCLUSTER
- CSV
- 还可以使用第三方存储引擎:
- MySQL当中插件式的存储引擎类型
- MySQL的两个分支
- perconaDB
- mariaDB
mysql> show engines
#查看当前MySQL支持的存储引擎类型
mysql> select table_schema,table_name,engine from information_schema.tables
where engine='innodb';
#查看innodb的表有哪些
mysql> select table_schema,table_name,engine from information_schema.tables
where engine='myisam';
#查看myisam的表有哪些innodb和myisam的区别
- 数据存放结构。InnoDB采用聚簇索引,数据文件和索引文件存放在一个表空间中,适合事务处理;MyISAM采用非聚簇索引,数据文件和索引文件是分开的,适合于全文搜索。
- 事务支持。InnoDB支持事务处理,提供ACID事务安全,适合于有事务需求的场景;MyISAM不支持事务处理,适合于不需要事务的场景。
- 锁机制。InnoDB支持行级锁,并发性能较高;MyISAM支持表级锁,并发性能相对较低。
- 外键支持。InnoDB支持外键,适合于有外键约束的表;MyISAM不支持外键。
- 全文索引。InnoDB不支持全文索引,可以通过插件支持;MyISAM支持全文索引。
- 性能和适用场景。InnoDB适合于处理大量数据和事务处理,适用于OLTP(Online Transaction Processing,在线事务处理)场景;MyISAM适合于数据仓库和全文搜索,适用于OLAP(Online Analytical Processing,在线分析处理)场景。
#进入mysql目录
[root@localhost~l]# cd /application/mysql/data/mysql
#查看所有user的文件
[root@localhost mysql]# ll user.*
-rw-rw---- 1 mysql mysql 10684 Mar 6 2017 user.frm
-rw-rw---- 1 mysql mysql 960 Aug 14 01:15 user.MYD
-rw-rw---- 1 mysql mysql 2048 Aug 14 01:15 user.MYI
#进入word目录
[root@localhost world]# cd /application/mysql/data/world/
#查看所有city的文件
[root@localhost world]# ll city.*
-rw-rw---- 1 mysql mysql 8710 Aug 14 16:23 city.frm
-rw-rw---- 1 mysql mysql 688128 Aug 14 16:23 city.ibdinnodb存储引擎的简介
- 在MySQL5.5版本之后,默认的存储引擎,提供高可靠性和高性能。
- 优点:
- 事务安全(遵从 ACID)
- MVCC(Multi-Versioning Concurrency Control,多版本并发控制)
- InnoDB 行级别锁定
- Oracle 样式一致非锁定读取
- 表数据进行整理来优化基于主键的查询
- 支持外键引用完整性约束
- 大型数据卷上的最大性能
- 将对表的查询与不同存储引擎混合
- 出现故障后快速自动恢复
- 用于在内存中缓存数据和索引的缓冲区池
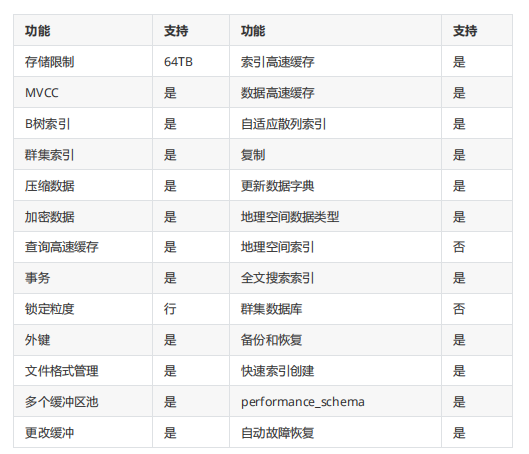
- innodb核心特性
- MVCC
- 事务
- 行级锁
- 热备份
- Crash Safe Recovery(自动故障恢复)
查看存储引擎
- 使用 SELECT 确认会话存储引擎
SELECT @@default_storage_engine;
# 查询默认存储引擎使用 SHOW 确认每个表的存储引擎
SHOW CREATE TABLE City\G
SHOW TABLE STATUS LIKE 'countrylanguage'\G
# 查看表的存储引擎使用 INFORMATION_SCHEMA 确认每个表的存储引擎
SELECT TABLE_NAME, ENGINE FROM INFORMATION_SCHEMA.TABLES WHERE TABLE_NAME = 'City' AND TABLE_SCHEMA = 'world'\G
# 查看表的存储引擎存储引擎的设置
- 在启动配置文件中设置服务器存储引擎
[mysqld]
default-storage-engine=<Storage Engine>
# 在配置文件的[mysqld]标签下添加使用 SET 命令为当前客户机会话设置
SET @@storage_engine=<Storage Engine>
# 在MySQL命令行中临时设置在 CREATE TABLE 语句指定
CREATE TABLE t (i INT) ENGINE = <Storage Engine>;
# 建表的时候指定存储引擎20.如何客户的数据库是myisam如何切换到innodb(大致步骤)
参考博客:
21.MySQL的日志都有哪些
7 种日志文件:
- 重做日志(redo log)
- 回滚日志(undo log)
- 二进制日志(bin log)
- 错误日志(error log)
- 慢查询日志(slow query log)
- 一般查询日志(general log)
- 中继日志(relay log)
22.什么是二进制日志binlog,row模式和statement模式的优缺点
- 记录已提交的DML事务语句,并拆分为多个事件(event)来进行记录
- 记录所有DDL、DCL等语句
- 总之,二进制日志会记录所有对数据库发生修改的操作
- 二进制日志模式
- statement:语句模式
- row:行模式,即数据行的变化过程
- mixed:以上两者的混合模式。
- 企业推荐使用row模式
- 二进制日志模式优缺点
- statement模式
- 优点:简单明了,容易被看懂,就是sql语句,记录时不需要太多的磁盘空间
- 缺点:记录不够严谨
- row模式
- 优点:记录更加严谨
- 缺点:有可能会需要更多的磁盘空间,不太容易被读懂
- statement模式
- binlog的作用
- 如果我拥有数据库搭建开始所有的二进制日志,那么我可以把数据恢复到任意时刻数据的备份恢复
- 数据的复制
说明:
MySQL 整体来看,其实就有两块:一块是 Server 层,它主要做的是 MySQL 功能层面的事情;还有一块是引擎层,负责存储相关的具体事宜。上面我们聊到的粉板 redo log 是 InnoDB 引擎特有的日志,而 Server 层也有自己的日志,称为 binlog(归档日志)。
我想你肯定会问,为什么会有两份日志呢?
因为最开始 MySQL 里并没有 InnoDB 引擎。MySQL 自带的引擎是 MyISAM,但是 MyISAM 没有 crash-safe 的能力,binlog 日志只能用于归档。而 InnoDB 是另一个公司以插件形式引入 MySQL 的,既然只依靠 binlog 是没有 crash-safe 能力的,所以 InnoDB 使用另外一套日志系统——也就是 redo log 来实现 crash-safe 能力。
这两种日志有以下三点不同。
redo log 是 InnoDB 引擎特有的;binlog 是 MySQL 的 Server 层实现的,所有引擎都可以使用。
redo log 是物理日志,记录的是“在某个数据页上做了什么修改”;binlog 是逻辑日志,记录的是这个语句的原始逻辑,比如“给 ID=2 这一行的 c 字段加 1 ”。
redo log 是循环写的,空间固定会用完;binlog 是可以追加写入的。“追加写”是指 binlog 文件写到一定大小后会切换到下一个,并不会覆盖以前的日志。
23.慢查询日志分析(mysqldumpslow)
- 是将mysql服务器中影响数据库性能的相关SQL语句记录到日志文件
- 通过对这些特殊的SQL语句分析,改进以达到提高数据库性能的目的
- 默认位置:
- MYSQL_HOME/data/MYSQLHOME/data/$hostname-slow.log
开启方式(默认没有开启)
[root@db01 ~]# vim /etc/my.cnf
[mysqld]
#指定是否开启慢查询日志
slow_query_log = 1
#指定慢日志文件存放位置(默认在data)
slow_query_log_file=/application/mysql/data/slow.log
#设定慢查询的阀值(默认10s)
long_query_time=0.05
#不使用索引的慢查询日志是否记录到索引
log_queries_not_using_indexes
#查询检查返回少于该参数指定行的SQL不被记录到慢查询日志
min_examined_row_limit=100(鸡肋)模拟慢查询语句
mysql> use world
#进入world库
mysql> show tables
#查看表
mysql> create table t1 select * from city;
#将city表中所有内容加到t1表中
mysql> desc t1;
#查看t1的表结构
mysql> insert into t1 select * from t1;
mysql> insert into t1 select * from t1;
mysql> insert into t1 select * from t1;
mysql> insert into t1 select * from t1;
#将t1表所有内容插入到t1表中(多插入几次)
mysql> commit;
#提交
mysql> delete from t1 where id>2000;
#删除t1表中id>2000的数据
[root@db01 ~]# cat /application/mysql/data/slow.log
#查看慢日志使用mysqldumpslow命令来分析慢查询日志
$PATH/mysqldumpslow -s c -t 10 /application/mysql/data/slow.log
#输出记录次数最多的10条SQL语句- 参数说明:
- -s:
- 是表示按照何种方式排序,c、t、l、r分别是按照记录次数、时间、查询时间、返回的记录数来排序,ac、at、al、ar,表示相应的倒叙;
- -t:
- 是top n的意思,即为返回前面多少条的数据;
- -g:
- 后边可以写一个正则匹配模式,大小写不敏感的;
- -s:
$PATH/mysqldumpslow -s r -t 10 /application/mysql/data/slow.log
#得到返回记录集最多的10个查询
$PATH/mysqldumpslow -s t -t 10 -g "left join" /application/mysql/data/slow.log
#得到按照时间排序的前10条里面含有左连接的查询语句24.MySQL的备份和恢复相关知识
参考博客:
25.MySQL服务损坏,且没有备份的情况下,数据库服务如何恢复
- 评估损坏程度:
- 首先,你需要确定MySQL服务损坏的具体原因。这可能是由于硬件故障、文件系统损坏、错误的升级操作或其他任何因素造成的。
- 查看MySQL的错误日志(通常是
/var/log/mysql/error.log)可以提供关于问题的更多信息。
- 数据恢复工具:
- 有一些商业和开源工具,如
Percona Toolkit或InnoDB Recovery Tools,它们可以帮助恢复损坏的InnoDB表。这些工具可能需要一定的技术知识来正确使用。 - 在使用这些工具之前,请确保你已经尝试重新启动MySQL服务并查看任何相关的错误消息。
- 有一些商业和开源工具,如
- 文件恢复:
- 如果MySQL的数据文件(通常是
.frm,.ibd, 或.myd,.myi文件,取决于存储引擎)受到损坏,你可以尝试使用文件系统级别的恢复工具(如extundelete对于ext3/ext4文件系统)来恢复这些文件。 - 请注意,这种方法可能并不总是有效,并且可能会增加数据丢失的风险。
- 如果MySQL的数据文件(通常是
- 从二进制日志恢复:
- 如果你的MySQL服务器配置了二进制日志(binary logs),你可以尝试使用这些日志来“重放”从最后一次备份以来发生的所有更改。
- 使用
mysqlbinlog工具来处理二进制日志文件,并使用它来将更改应用到一个新的数据库副本。
参考博客:
看二进制日志恢复部分
26.MySQL双主架构原理
参考博客:https://www.cnblogs.com/jpfss/p/11577924.html
27.MySQL双主架构一致性的问题
参考博客:https://zhuanlan.zhihu.com/p/633225438?utm_id=0
28.MySQL主从架构原理
- 复制是 MySQL 的一项功能,允许服务器将更改从一个实例复制到另一个实例。
- 主服务器将所有数据和结构更改记录到二进制日志中。
- 从属服务器从主服务器请求该二进制日志并在本地应用其内容。
- IO 线程:请求主库,获取上一次执行过的新的事件,并存放到relaylog
- SQL 线程:从relaylog中将sql语句翻译给从库执行
- 主从复制的前提
- 两台或两台以上的数据库实例
- 主库要开启二进制日志
- 主库要有复制用户
- 主库的server_id和从库不同
- 从库需要在开启复制功能前,要获取到主库之前的数据(主库备份,并且记录binlog当时位置)
- 从库在第一次开启主从复制时,时必须获知主库:ip,port,user,password,logfile,pos
- 从库要开启相关线程:IO、SQL
- 从库需要记录复制相关用户信息,还应该记录到上次已经从主库请求到哪个二进制日志
- 从库请求过来的binlog,首先要存下来,并且执行binlog,执行过的信息保存下来
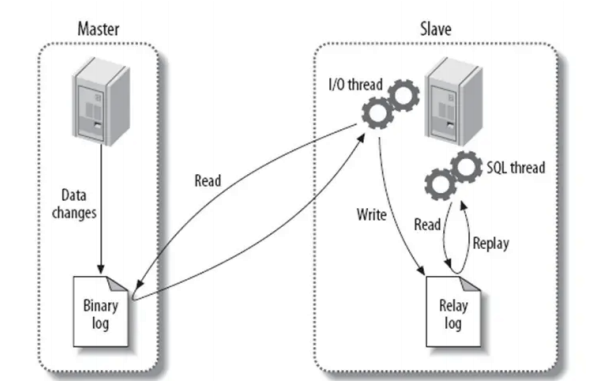
- 主从复制涉及到的文件和线程
- 主库:
- 主库binlog:记录主库发生过的修改事件
- dump thread:给从库传送(TP)二进制日志线程
- 从库:
- relay-log(中继日志):存储所有主库TP过来的binlog事件
- master.info:存储复制用户信息,上次请求到的主库binlog位置点
- IO thread:接收主库发来的binlog日志,也是从库请求主库的线程
- SQL thread:执行主库TP过来的日志
- 主库:
- 原理
- 通过change master to语句告诉从库主库的ip,port,user,password,file,pos
- 从库通过start slave命令开启复制必要的IO线程和SQL线程
- 从库通过IO线程拿着change master to用户密码相关信息,连接主库,验证合法性
- 从库连接成功后,会根据binlog的pos问主库,有没有比这个更新的
- 主库接收到从库请求后,比较一下binlog信息,如果有就将最新数据通过dump线程给从库IO线程
- 从库通过IO线程接收到主库发来的binlog事件,存储到TCP/IP缓存中,并返回ACK更新master.info
- 将TCP/IP缓存中的内容存到relay-log中
- SQL线程读取relay-log.info,读取到上次已经执行过的relay-log位置点,继续执行后续的relay-log日志,执行完成后,更新relay-log.info
29.主从架构存在的问题,解决思路
问题一:主库的从库太多,导致复制延迟
- 从库数量以3~5个为宜,要复制的从节点数量过多,会导致复制延迟。
问题二:从库硬件比主库差,导致复制延迟。
- 查看Master和Slave的系统配置,可能会因为机器配置不当,包括磁盘I/O,CPU,内存 等各方面因素造成复制的延迟。这一般发生在高并发大数据量写入场景中。
问题三:慢SQL语句太多
- 假如一条SQL语句执行时间是20秒,那么从执行完毕到从库上能查到数据至少需要20 秒,这样就延迟20秒了。 一般要把SQL语句的优化作为常规工作,不断的进行监控和优化,如果单个SQL的写入时 间长,可以修改后分多次写入。通过查看慢查询日志或show full processlist命令,找出 执行时间长的查询语句或大的事务。
问题四:主从复制的设计问题
- 例如,主从复制单线程,如果主库写并发太大,来不及传送到从库,就会导致延迟。 更高版本的MySQL可以支持多线程复制,门户网站则会自己开发多线程同步功能。
问题五:主从库之间的网络延迟
- 主从库的网卡,网线,连接的交换机等网络设备都可能成为复制的瓶颈,导致复制延 迟,另外,跨公网主从复制很容易导致主从复制延迟。
问题六:主库读写压力大,导致复制延迟。
- 主库硬件要搞好一点,架构的前端要加buffer及缓存层。
1.MySQL数据库主从同步延迟原理。
- 答:谈到mysql数据库主从同步延迟原理,得从mysql的数据库主从复制原理说起,mysql的主从复制都是单线程的操作,主库对所有DDL和DML产生binlog,binlog是顺序写,所以效率很高;slave的Slave_IO_Running线程会到主库取日志,效率会比较高,slave的Slave_SQL_Running线程将主库的DDL和DML操作都在slave实施。DML和DDL的IO操作是随机的,不是顺序的,因此成本会很高,还可能是slave上的其他查询产生lock争用,由于Slave_SQL_Running也是单线程的,所以一个DDL卡主了,需要执行10分钟,那么所有之后的DDL会等待这个DDL执行完才会继续执行,这就导致了延时。有朋友会问:“主库上那个相同的DDL也需要执行10分,为什么slave会延时?”,答案是master可以并发,Slave_SQL_Running线程却不可以。
2.MySQL数据库主从同步延迟是怎么产生的。
- 答:当主库的TPS并发较高时,产生的DDL数量超过slave一个sql线程所能承受的范围,那么延时就产生了,当然还有就是可能与slave的大型query语句产生了锁等待。
3.MySQL数据库主从同步延迟解决方案
- 答:最简单的减少slave同步延时的方案就是在架构上做优化,尽量让主库的DDL快速执行。还有就是主库是写,对数据安全性较高,比如sync_binlog=1,innodb_flush_log_at_trx_commit = 1 之类的设置,而slave则不需要这么高的数据安全,完全可以讲sync_binlog设置为0或者关闭binlog,innodb_flushlog也可以设置为0来提高sql的执行效率。另外就是使用比主库更好的硬件设备作为slave。
4.MySQL数据库主从同步延迟产生的因素。
- 网络延迟
- master负载
- slave负载 一般的做法是,使用多台slave来分摊读请求,再从这些slave中取一台专用的服务器,只作为备份用,不进行其他任何操作,就能相对最大限度地达到’实时’的要求
另外,再介绍2个可以减少延迟的参数
- –slave-net-timeout=seconds
- 参数含义:当slave从主数据库读取log数据失败后,等待多久重新建立连接并获取数据 slave_net_timeout单位为秒 默认设置为 3600秒
- –master-connect-retry=seconds
- 参数含义:当重新建立主从连接时,如果连接建立失败,间隔多久后重试。 master-connect-retry单位为秒 默认设置为 60秒 通常配置以上2个参数可以减少网络问题导致的主从数据同步延迟
30.主从复制,从库误操作写入数据怎么办(主从不同步,会导致SQL线程停止)
一、问题描述
【ERROR】1062: 从库插入数据,发生唯一性冲突
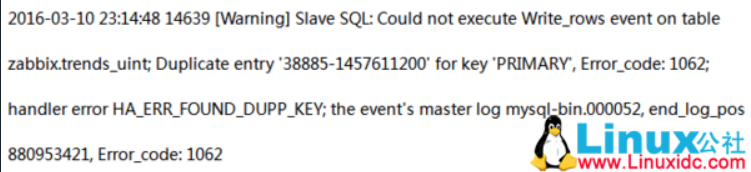
二、原因分析
【ERROR】1062: 从库插入数据,发生唯一性冲突。此时从库已经有相同主键的数据,如果再插入相同主键值的数据则会报错。可以查看主库的改行数据与从库的要插入数据是否一致,如一致则跳过错误,恢复 SQL 线程,如不一致,则以主库为准,将从库的该行记录删除,再开启复制。
如果当前高可用架构为 Master-Master,则以下均在从库的操作都必须 set sql_log_bin=0,避免从库执行的语句同步到主库(恢复时以主库的数据为准)。
三、标准化处理方案
1.【ERROR】1062解决方案:

普通主从复制环境
从库:

主库:
查看主库在出错的相应位置的执行语句,可通过 SQL 得出当时 insert 的对应的主键值。

查询 trends_uint 表对应主键值的数据行。
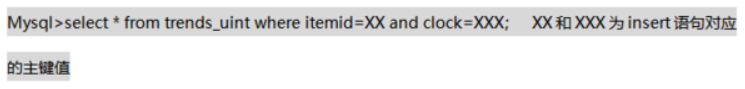
从库:
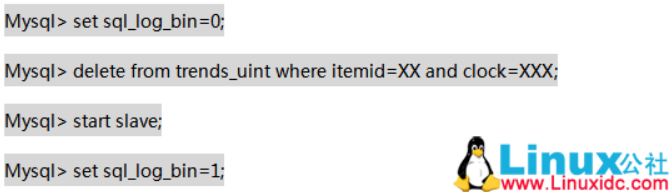
在 trends_uint 表删除主库查询出来的数据。
基于 GTID 复制环境
与普通主从复制环境处理方式相同。
2.彻底解决方案
使用 pt-table-checksum 和 pt-table-sync 彻底修复数据不一致。
注意:使用 pt 工具包首先要安装 pt 工具包和安装 perl 模块。
(1) 从库停止复制

(2) 在主库创建校验信息表

(3) 在主库用 pt-table-checksum 校验主从数据一致性
在从库执行以下语句,查看 Last_Error,发现数据不一致的表:
然后返回操作系统执行以下命令:

该命令可以查看该表是否发生数据不一致情况,若有,则使用 pt-table-sync 修复。
(4) 在主库用 pt-table-sync 打印出修复不一致数据的 SQL(如果有外键约束,修复数据应先从外键参考的字段所属表开始修复),后将修复语句在从库执行。

31.主从复制,从库IO线程故障排查思路
IO线程故障
当状态为No时表示IO线程故障,如下
Slave_IO_Running: No
分为两种情况
1、Connecting出错
2、请求Binlog出错
Connecting出错可能原因
1、网络不通,防火墙拦截
2、复制用户密码错误,权限错误,权限为replication slave
3、主库连接数达到上限,默认连接151个并发会话
4、版本不一致导致,如mysql8.0使用的sha2验证方式,MySQL5.7采用的native验证方式导致连接不上
请求Binlog出错可能原因
1、请求的binlog在主库被清理,误删除,不完整等
2、主库binlog 没开
3、从库请求的起点不存在
4、主从的server_id或server_uuid相同
排查思路
1、使用复制账号密码在从库进行手工登录,如mysql -urepl -p123 -h 10.154.0.111 -P 3306
2、查看data/client2.err错误日志
3、配置文件是否跟主库一致
MySQL连接数上限默认151个
mysql> select @@max_connections;
+-------------------+
| @@max_connections |
+-------------------+
| 151 |
+-------------------+
1 row in set (0.00 sec)常见Connecting错误代码的含义
#账号或密码错误
Last_IO_Errno: 1045
Last_IO_Error: error connecting to master 'relp@10.154.0.111:3306' - retry-time: 10 retries: 1
#IP地址错误
Last_IO_Errno: 2003 (HY000)
Last_IO_Error:Can't connect to MySQL server on '10.0.0.52' (113)
#端口错误
Last_IO_Errno: 2003 (HY000)
Last_IO_Errno: Can't connect to MySQL server on '10.0.0.51' (111)
#连接数超出限制
Last_IO_Errno: 1040 (08004)
Last_IO_Errno: Too many connections
参考博客:https://blog.51cto.com/u_16099229/648209432.主从复制中的延时从库,半同步复制,过滤复制使用场景
- 延时从库:
- 延时从库是指在主从复制中,特意设置从库的复制延迟,使得从库的数据相对于主库来说有一定的时间延迟。这种设置可以用于避免一些突发情况对主库进行写入数据的影响,同时也可以用于数据恢复和数据分析等场景。比如,在某些应用场景下,需要保留一段时间内的历史数据,可以通过设置延时从库来实现。延时从库也常用于灾备架构中,这样在灾难发生时可以及时切换到延时从库上继续提供服务,保证系统的可用性。
- 半同步复制:
- 半同步复制是指在主从复制中,主库在将数据发送给从库之前,需要等待至少一个从库将数据已经接收成功。只有当至少一个从库确认接收成功后,主库才会进行下一步的操作。这种方式可以有效地降低由于从库延迟造成的数据不一致问题。在对数据一致性要求较高的场景中,半同步复制是一种较好的选择。例如,在某些金融支付系统或者实时数据备份场景中,由于数据一致性很重要,使用半同步复制可以保证数据在各个节点上的一致性。
- 过滤复制:
- 过滤复制是指在主从复制中,通过设置过滤规则,只复制指定的数据或者排除指定的数据进行复制。这种方式可以有效地减少网络带宽的压力,提高数据复制的效率。过滤复制可以基于数据库的某些特定条件来进行过滤,如只复制满足某些条件的表或特定列的数据。过滤复制可以应用于一些特定需求的场景,如只需要复制某个特定用户的数据到从库中进行分析。通过过滤复制,可以灵活控制主从复制的数据流量,提高整体系统的性能。
33.MySQL的MHA高可用架构的原理
- MHA(Master High Availability)目前在MySQL高可用方面是一个相对成熟的解决方案,它由日本DeNA公司youshimaton(现就职于Facebook公司)开发,是一套优秀的作为MySQL高可用性环境下故障切换和主从提升的高可用软件。在MySQL故障切换过程中,MHA能做到在0~30秒之内自动完成数据库的故障切换操作,并且在进行故障切换的过程中,MHA能在最大程度上保证数据的一致性,以达到真正意义上的高可用。
- MHA能够在较短的时间内实现自动故障检测和故障转移,通常在10-30秒以内;在复制框架中,MHA能够很好地解决复制过程中的数据一致性问题,由于不需要在现有的replication中添加额外的服务器,仅需要一个manager节点,而一个Manager能管理多套复制,所以能大大地节约服务器的数量;另外,安装简单,无性能损耗,以及不需要修改现有的复制部署也是它的优势之处。
- MHA还提供在线主库切换的功能,能够安全地切换当前运行的主库到一个新的主库中(通过将从库提升为主库),大概0.5-2秒内即可完成。
- MHA由两部分组成:MHA Manager(管理节点)和MHA Node(数据节点)。MHA Manager可以独立部署在一台独立的机器上管理多个Master-Slave集群,也可以部署在一台Slave上。当Master出现故障时,它可以自动将最新数据的Slave提升为新的Master,然后将所有其他的Slave重新指向新Master。整个故障转移过程对应用程序是完全透明的。
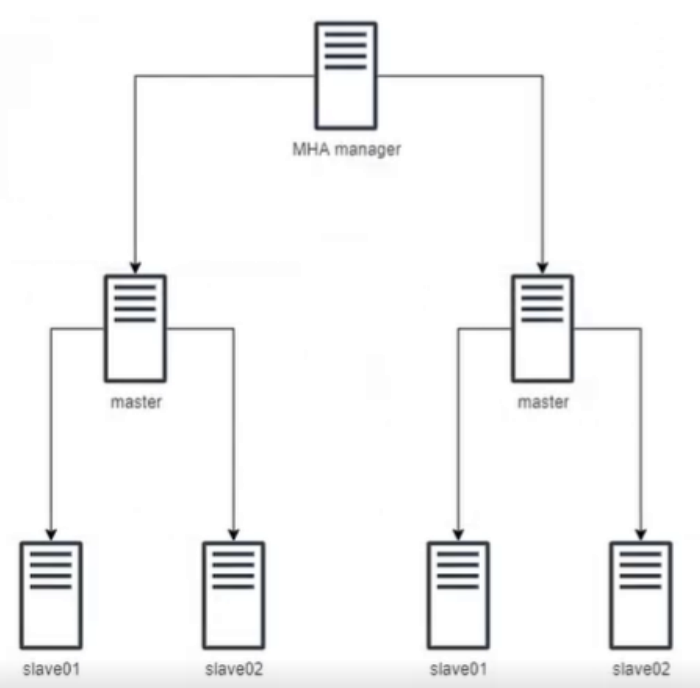
工作流程
- 1. 把宕机的master二进制日志保存下来。
- 2. 找到binlog位置点最新的slave。
- 3. 在binlog位置点最新的slave上用relay log(差异日志)修复其它slave。
- 4. 将宕机的master上保存下来的二进制日志恢复到含有最新位置点的slave上。
- 5. 将含有最新位置点binlog所在的slave提升为master。
- 6. 将其它slave重新指向新提升的master,并开启主从复制。
34.如何部署MHA高可用架构
参考博客: